












- Home
- >
- Software Development
- >
- 12 Commands to Debug Your Workloads – InApps Technology 2022
12 Commands to Debug Your Workloads – InApps Technology is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn 12 Commands to Debug Your Workloads – InApps Technology in today’s post !
Read more about 12 Commands to Debug Your Workloads – InApps Technology at Wikipedia
You can find content about 12 Commands to Debug Your Workloads – InApps Technology from the Wikipedia website

Justin Garrison
Justin is a senior developer advocate at Amazon Web Services (AWS).
In my previous article, I showed you how to debug a Kubernetes cluster in eight commands. Now we need to look at what happens when your workloads are not working as you might expect.
It doesn’t matter if you get the dreaded CrashLoopBack or other failures. The commands here will help you narrow down workload problems, so you can fix them. We’ll stick with commands that should work in any cluster, no matter where you run it. We also won’t assume you have centralized metrics or logging outside of installing a metrics server.
Most of the commands will use kubectl commands or plugins which you can install via krew. If you don’t want to use the plugins, you can usually get the same information from kubectl, but the plugins will format the data to make it easier to debug.
We will make the assumption that your code works, and you know which application is broken and where it’s running. Kubernetes can’t fix broken code. But if your container won’t start or the application gets intermittent errors, here’s where you can start. We’ll skip specifics — such as finding which cluster, region or namespace the application is running, or which version is current — because those will be unique to your environment.
There are different types of workload errors, so we’ll break it down into three stages of troubleshooting:
- Workloads won’t run
- Cannot access workloads
- Debug specific pods
The example commands and screenshots use a dummy workload called “spider,” so any time you see spider*, $LABEL or $POD in a command, you should replace it with your workload name.
Workloads Won’t Run
|
kubectl get events —field–selector type=Warning —all–namespaces kubectl get nodes –o wide —label–columns topology.kubernetes.io/zone kubectl resource–capacity —pods —util —sort cpu.util kubectl get all —show–labels kubectl lineage pod ${POD} kail –l ${LABEL} |
This first category of errors applies to all workloads in a cluster. It doesn’t matter if it is a deployment, DaemonSet or cron job. In each case, the thing that runs on your nodes is a group of containers known as a pod. Pods are the smallest unit of work in Kubernetes, so it’s not surprising we need to look at pods to fix application issues.
Just like with cluster troubleshooting, you should start with a breadth-first approach and narrow in on specific problems. The application probably isn’t failing everywhere, so we should first look at where it is failing, what has changed, and what is different.
The example commands we’ll use will only look at the default namespaces, but you should add -n $NAMESPACE for your particular workloads. The ultimate goal of all of these commands is to get you to the log line or error message that says why something didn’t run. That could be from your infrastructure provider, a Kubernetes controller or your application.
1. kubectl get events –field-selector type=Warning –all-namespaces

First we should start as broad as possible in the cluster. Depending on how large and how many workloads are in your cluster, this command might have a lot of output. In smaller clusters, it could have just enough to point out some obvious problems for why a workload isn’t working.
You will likely see errors with controllers and Kubernetes components in this command, which might show you why or where something failed. In our example screenshot, you can see that there are warnings because we couldn’t allocate an IP address to the pods. We would probably see these same errors in the kubelet logs, but looking at all warnings in a cluster will show us how errors might cascade into different controllers.
2. kubectl get nodes -o wide –label-columns topology.kubernetes.io/zone

This output is fairly common for any debugging process. You should be able to quickly identify any nodes that are not in a “ready“ state or that might have different versions of the kubelet or a different container runtime. By adding the topology zone output, you can also see if any of your node problems are related to a specific zone, which might be having other problems such as a network partition or a dependent service is unavailable.
3. kubectl resource-capacity –pods –util –sort cpu.util

Even in the world of containers, you’re still going to have to deal with CPU and memory resources. The resource-capacity plugin can save you a lot of commands to figure out how a node is being used and which pods might be using more resources than they should be. You can install the plugin with kubectl krew install resource-capacity.
It’s important to note: This plugin requires that you have the metrics-server installed in your cluster. Once you have it running, you should be able to use this command to find potential problems where resources are limited or where pods do not have limits set.
4. kubectl get all –show-labels

This command won’t show us everything, but what we’re really concerned with is deployment, pods and services. By including the labels for each workload, we can see things like the pod-template-hash label, which will give us a hash value you can match between our deployment and pod. If any pods are not running, we know where to look next.
At this point it’s good to look at the service too, to see what type it is. If it’s a LoadBalancer type, then you should make sure a load balancer has been provisioned. If all your pods are running, then the application problem might not be from the pods. Just in case, we should grab one of the pod names so that we can inspect it more in the next few commands.
5. kubectl lineage pod ${POD}

The lineage command is another kubectl plugin that can show what created a resource in Kubernetes and what depends on it. If you’ve ever used kubectl tree, you’ll be familiar with lineage, but lineage has a few extra features. You can install the lineage plugin with kubectl krew install lineage.
One of my favorite features about this command is that not only does it show the Kubernetes resources like ReplicaSets and services in the cluster, but it also shows events, RBAC (role-based access control), nodes, and has native helm support. By default, the command will show dependents, but with the --dependencies flag you can see what depends on a resource.
Just for fun, you can look at a service like the metrics-server and see all of the ClusterRoleBindings as well as the pods and nodes behind the service.

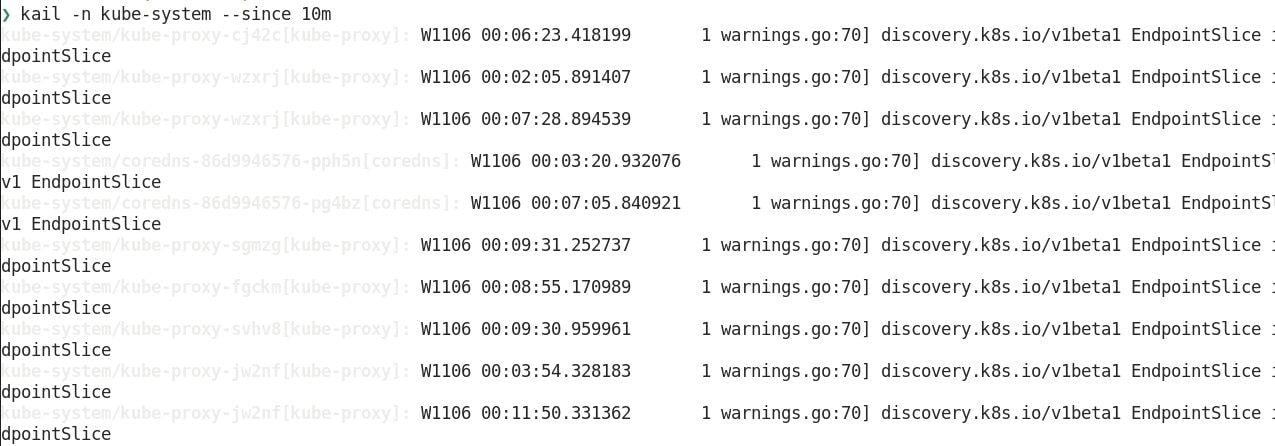
6. kail -l ${LABEL}

Our last workload troubleshooting command will show us all the logs for a workload based on a label. kail is a standalone tool, instead of a kubectl plugin, that can be installed with brew install boz/repo/kail. The benefit of making it standalone is that it can do some things that normally would be hard with a single kubectl command.
For example, you can get all logs from a specific namespace with --ns or all of the pods behind an ingress rule with --ing.
Cannot Access Workloads
|
kubectl get service –o wide kubectl get endpointslices –o wide kubectl port–forward deploy $DEPLOYMENT $LOCAL_PORT:$POD_PORT |
7. kubectl get service -o wide

The first thing you should look at are the services in the cluster, because that’s the main way traffic will be routed in and out of the cluster. If you’re using ingress for traffic routing, then you’ll also want to use kubectl get ingress -o wide. The important thing to check is what type of service it is, if there’s an external IP address or load balancer, and what labels are used.
From the data we collected from listing workloads earlier, we should be able to compare the labels being used on the pods with the matching labels on the service. If they don’t match, they won’t be part of the EndpointSlice.
8. kubectl get endpointslices -o wide

The next thing we can look at are EndpointSlices. This will show us each of our services in the namespace and which pod IP addresses are associated with that service. If you see services without any endpoints, then you need to verify that the pods are ready and the labels match.
9. kubectl port-forward deploy/$DEPLOYMENT $LOCAL_PORT:$POD_PORT
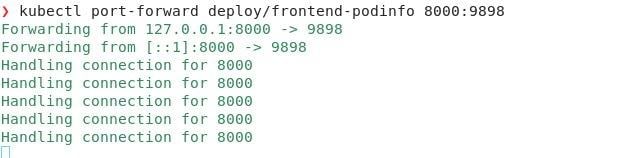
This command will let us bypass the load balancer or ingress controller to see if we can send traffic directly to one of the pods in the deployment. You can also port-forward traffic directly to a pod, if you have one that you suspect is having problems. This will help us rule out errors with our service, load balancer and some network configurations, because your connection goes through the Kubernetes API server.
Debug Specific Pods
|
kubectl debug –it —image=debian $POD kubectl label pod $POD app– kubectl blame pod |
If we’ve gone this far and still have not solved the problem, there are a few additional commands we can use to look at specific pods, to see if we can identify what’s going on.
10. kubectl debug pod –it –image=debian $POD

The debug command requires ephemeral containers to be enabled on your cluster. Currently this is an alpha feature with Kubernetes 1.22, so it may not be available in your cluster yet.
Sometimes the fastest way to solve a problem is with an interactive shell. There are a few different ways you can get a shell in a running pod, but debug is my favorite. The debug command is different from exec because exec requires that your pod already has debugging tools installed in the pod. However, the debug command will let you specify a new container that you can “mount” to the running pod and then bring your own tools.
You can supply whatever container you want with tools for your --image; different errors might require different tools. I usually have a dedicated debugging container with pre-installed tools, but if you don’t have one around, you can use a full distro that you’re familiar with to install whatever tools you need. One cool thing about using an ephemeral container to debug something is that this also works for static binary containers that were built FROM scratch and have no other files or package managers.
The debug command can also be used to get an interactive shell on the node. This is similar to SSHing into the node, but the debug command runs the container in privileged mode with your tools installed. This is especially useful if you’re using a minimal container OS or do not configure SSH access on the nodes.
There are some more options on getting an interactive shell to a pod in the Kubernetes documentation.
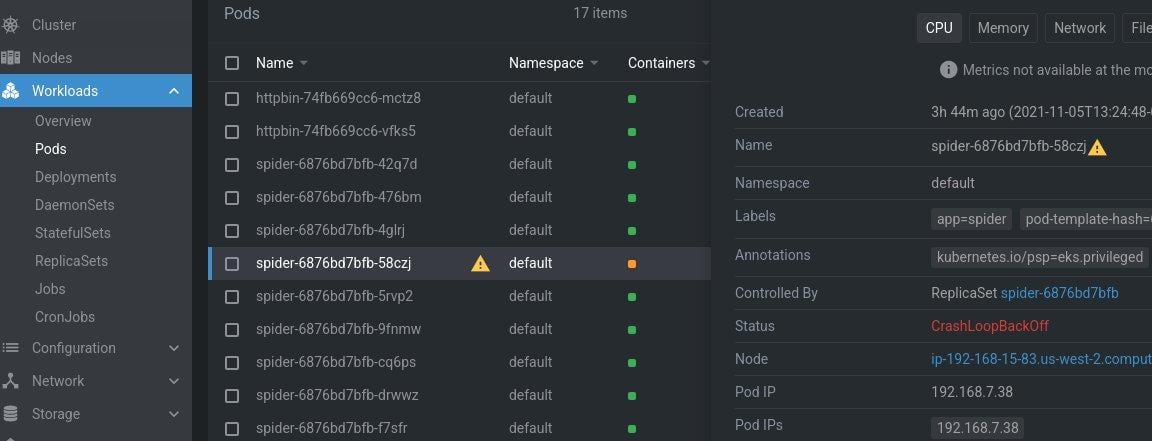
11. kubectl label pod $POD app-

This is one of my favorite debugging commands in Kubernetes. By default, a deployment will add a label to your pods, such as app=nginx. When you expose the deployment with a service, it also matches on that label. By running this command, you’re removing the app label from the pod.
Because the replication controller and service objects match labels, once you remove the app label, a new pod will replace the pod you removed the label from, but it will leave your pod running. You now have a pod you can troubleshoot without worrying about sending it production traffic or the pod being scaled up or down from a horizontal pod autoscaler. The pod is effectively not tracked when you remove the labels.
In the screenshot, you can see that I removed the app label from the httpbin pod, which caused a new pod to replace it in the ReplicaSet and left the old pod available for me to debug.
12. kubectl blame pod $POD

The blame command is a great plugin you can use to see what parts of a pod manifest have changed and who or what changed them. You can install it with kubectl krew install blame. With this output, you can quickly figure out what controllers modified the manifest and maybe look at those components to see why they changed it.
The output here isn’t perfect; it won’t show every modification to a manifest. Some of the fields are modified before they’re stored in etcd because of webhooks or default values. But it’s still incredibly powerful to know how often a field is changing and what controllers are modifying which fields in the manifest.
Honorable Mentions
There were some other plugins that can dive a lot deeper into workloads, but some of them require specific features in your cluster or additional daemons on the nodes. Two worth mentioning are inspecktor-gadget, which can be installed with kubectl krew install gadget, and kubectl-capture, which creates capture files you can replay using tools like sysdig-inspect.
Both of these plugins require you to install DaemonSets on the nodes, but they can be extremely powerful if you need to dive deeper into problems with your workload. They both use kernel-level applications, using eBPF to understand everything happening.
UI Options for Debugging Workloads
All of these commands are great to get you started. You should be able to understand more about your workloads and figure out what is going wrong. There are other options for troubleshooting that are also worth mentioning. In some cases, these UIs can combine information from multiple of these commands in the same screen.
The first one to mention is k9s. This tool runs in your terminal as a terminal user interface (TUI) and makes it easier to navigate your resources and see additional information. You can install k9s from the GitHub repo and start using it with any Kubernetes cluster.
https://github.com/derailed/k9s

Another option is Lens from Mirantis. Lens is a standalone application that has the ability to quickly switch Kubernetes clusters and brings in a lot of additional information for whatever you’re troubleshooting. Lens is a great option if you want a more fully featured Kubernetes UI. You can install it from https://k8slens.dev/.
InApps Technology is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Mirantis.
Photo by Egor Kamelev from Pexels.
Source: InApps.net
Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.












