












- Home
- >
- Software Development
- >
- Amazon SageMaker Automates the Artificial Intelligence Development Pipeline – InApps 2022
Amazon SageMaker Automates the Artificial Intelligence Development Pipeline – InApps is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn Amazon SageMaker Automates the Artificial Intelligence Development Pipeline – InApps in today’s post !
Read more about Amazon SageMaker Automates the Artificial Intelligence Development Pipeline – InApps at Wikipedia
You can find content about Amazon SageMaker Automates the Artificial Intelligence Development Pipeline – InApps from the Wikipedia website
With the debut of Amazon SageMaker last week, Amazon Web Services has gone a long way towards incorporating machine learning into professional development and deployment pipelines. And a new video camera from the company, AWS DeepLens, was designed to help developers better understand how to create ML and AI technologies.
The company showed off these new artificial intelligence technologies at the company’s Re:Invent user conference, being held this week in Las Vegas.
The idea behind SageMaker is to accelerate the process of developing/refining machine learning models and integrating them into a development pipeline. In SageMaker, the preliminary editing of machine learning models is done in Jupyter notebooks, and tested on AWS virtual machines, either general instances or the GPU-powered variety. The data is read from AWS’ Simple Storage Service (S3) buckets and the results — the data dependent model parameters commonly known as model artifacts — are placed back into S3. A third part of the service offers model hosting, via a scalable HTTPs endpoint that can be called by an application to get real-time inferences.
At the event, we spoke with Lowell Anderson, AWS general manager of product marketing, to learn more about SageMaker. Before coming to AWS, Anderson ran the virtual machine and container program for Parallels. So we quizzed him about other technologies introduced at the conference as well, including the new supported Kubernetes service, the Fargate managed container service, and the Aurora and DynamoDB database updates.
Could you explain how SageMaker can speed the production workflow for the development of AI-based applications?
Building and training [machine learning] models are really, really difficult on your own. You need to be able to have a lot of specialized expertise to even understand the different types of algorithms that you use to train the model and then to select those ones for the particular use case that you have.
Once you select that training algorithm, you have to have the data there to train against. You have to be able to set up all the infrastructure that’s required to process that training, and that requires a significant amount of compute nodes.
Trying to do all that on your own is pretty much beyond the capabilities of any normal application developer.
With SageMaker, we have 10 of the most common models already built and optimized within Jupyter Notebooks that you can select as part of the service. And that’s simple as just going in and choosing the correct algorithm that you want to run against your training set. Then if you have your data already in S3, you don’t have to move the data. So it operates right against the data in S3.
So that’s huge. Just being able to do that to be able to run training on data that you already have in S3, to be able to go to the SageMaker console and pick from 10 different algorithms that are already been pre-trained, pick your framework that you want to run in and get all that set up and pointed at your dataset without having to write any code is a huge change in how you would have to do this today.
Once you get that setup, it’s seriously is as easy as just hitting the thing saying, “Train the model.”
You have to decide how much time and money you want to spend training this model. You have a choice of how much compute power you want to put to this task. And some of these models, the developer might want to iterate quickly, put a lot of compute behind it so it runs fast. But if you can wait four or five days and let the models run pretty slow, you can save a lot of money by only applying a couple of compute instances to it.
So, SageMaker lets you make those choices. And then you just hit train and it provisions the instances, scales them out, deploys the framework onto those nodes, deploys the algorithm within that framework, points it at the training dataset that you’ve already picked out, runs that training and creates the output from it. Then SageMaker sets it up for you to be able to tune in and measure the output, and then your model is complete.
And then, once the developer has a model that they think works, and they want to use it in the application, they need to perform inference to create predictions off the new data that comes in. And that requires in itself a tremendous amount of compute power. Normally, you would have to build out a cluster on Elastic Cloud Compute (EC2) instances, deploy your existing model on it, build code that applies the model and matches it against data as it streams in.
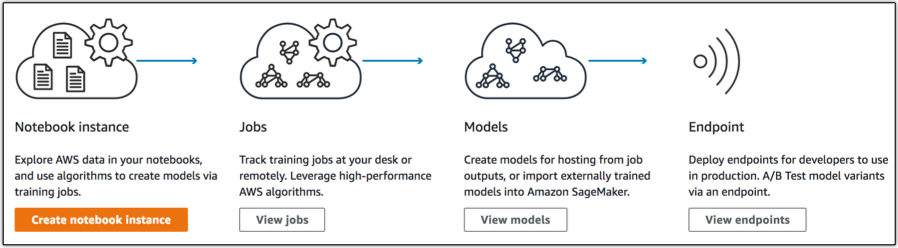
We do all that for you, too. You just deploy your model on a cluster and we set it all up and provide you with an HTTP endpoint for that model. So any application can just write to that HTTP endpoint and receive an inference result back from it. We’ll scale the cluster underneath to be able to return those results as fast as you need them.
So, what SageMaker really does is set up the ability for you to go into production at very, very high rate of inference without having to manage any of that infrastructure.
Containers
Tell us about the new Elastic Container Service for Kubernetes…
We launched the Elastic Container Service about four years ago now. At that time, Kubernetes wasn’t super popular. But in the last couple of years, as you know, this really passionate and really robust ecosystem has developed around Kubernetes. It has a lot of good tooling and a well-established developer community. So we have a lot of customers on AWS today who are running Kubernetes on EC2. In fact, about 80 percent of all cloud Kubernetes deployments today are running on AWS.
Those customers have been deploying Kubernetes containers on the premises, using them in development and so on. And when they want to take them to production, it’s super easy. This is the whole benefit of containers of course, the portability. They can have their Kubernetes installments on premises and then move those containers up to the cloud and run a Kubernetes deployment on EC2 in the cloud and just scale it out with AWS.
About 80 percent of all cloud Kubernetes deployments today are running on AWS.
So that’s what they’ve have been doing for the last couple of years. But, of course, that requires them to manage all those EC2 instances. As they need to expand the size of the control plane, they need to add more instances. As they reduce the size of the application, they have to be careful that they automatically de-provision those instances so they don’t pay more than they need to.
When you run your own Kubernetes on AWS, you really have to carefully manage the underlying infrastructure to make sure that it’s scaling up and scaling down, and you have to keep those instances maintained and set up your own Elastic Load Balancing to make sure it all stays balanced.
It’s doable, but it takes some time to manage and set that all up, which is really not the vision of containers, right? The vision of container is, you don’t have to mess with the infrastructure, you build your application into this nice portable container or task and you just can run it when you want to run it.
What we’re trying to do for those customers is just allow them to maintain that portability, but take away all the infrastructure management. So what we’ve done with the EKS service is just provided a fully-managed Kubernetes service on AWS. So they don’t have to manage or deploy any of the underlying EC2 Infrastructure.
Now, when you say you don’t have to manage resources, what specific elements are you referring to?
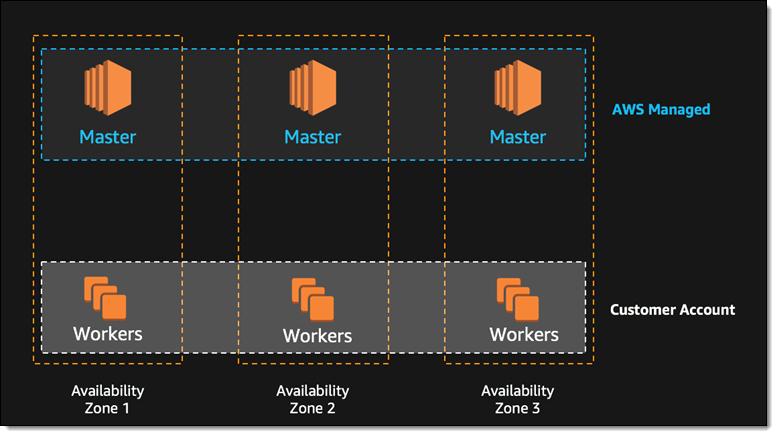
First of all, if you want to deploy it yourself on EC2, you’ve got to go get the Kubernetes software. You’ve got to set up a master node. If you want to make that master node redundant, then you have to do a bunch of work to make sure that that thing is duplicated across area zones. That requires a lot of manual labor on your part. Most people don’t do that. They just deploy a single master node and then they have to provision additional EC2 containers as they scale for other nodes.
And they still have to maintain the Kubernetes software. So whenever there’s a Kubernetes upgrade, they have to upgrade it. They have to maintain their master node. They have to make sure that it’s the correct size and scale the instance type as they grow the control plane. And then that doesn’t grow across area zones and across regions. You would have to create another different master node because the EC2 control plane or the Kubernetes control plane only runs on a single master.
So you’ve kind of inherently limited by that architecture by how much you can scale. All that goes away with EKS.
We set up the infrastructure with a fully, highly-available master node. We’re actually the only managed Kubernetes service that does that. So when you deploy your EKS containers onto AWS, there’s no single point failure. We’ve built out the underlying infrastructure so the Kubernetes control plane is highly available: We have dual redundant backup master nodes in case of any kind of failure.
We also manage and keep Kubernetes upgraded to the latest open source release, so you don’t have to worry about managing or deploying any of the actual Kubernetes layer yourself either.
How is Fargate different than either ECS or the managed Kubernetes offering?
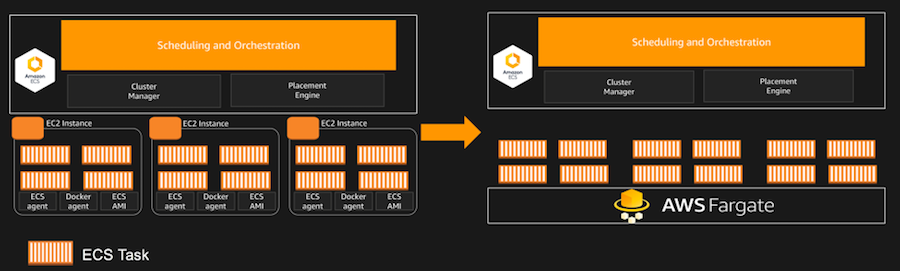
So today with ECS, when you want to expand your cluster, you do have to provision additional EC2 nodes, and then you have to deprovision then. What Fargate does is take all that away and effectively make it serverless.
So, instead of paying per EC2 node, which is how you paid before, you are just setting the total amount of compute that you want to run and then we’ll just dynamically scale the underlying infrastructure.
It’s purely what we could call a task. You’re no longer worrying about, “How many EC2 instances do I have to deploy? What types of the EC2 instances should I deploy?” How do I set up my Elastic Load Balancer?” All that goes away.
So both the orchestration layer – which is the part that controls and manages the scheduling of containers – and the underlying infrastructure itself, is completed abstracted away. All your doing is going to our console and specifying, “I want to run a container of this size, this much CPU and this much memory.” And it will scale on demand.
Databases
There seems to have been a lot of good work that went into Aurora this past year. The database service can now have multiple write master nodes? This seems like a game-changer of sorts….
Yeah. So today, there’s no other cloud database that supports multi-master write and reads.
Prior to today, what we had with Aurora is, we had a single master node that you could write to and then we would have multiple read nodes. In that situation, we could lose a read node and there would be an automatic backup for it already available for you. If the master write node failed, it took us about 30 seconds to bring up a new master node. And the way we would do that is we would take one of the read nodes and we’d reconfigure it as a write node, the master node.
Thirty-seconds is pretty fast, there’s no on-premise database could ever do that. But still, you don’t want your application down for 30 seconds if you’re running a critical web app.
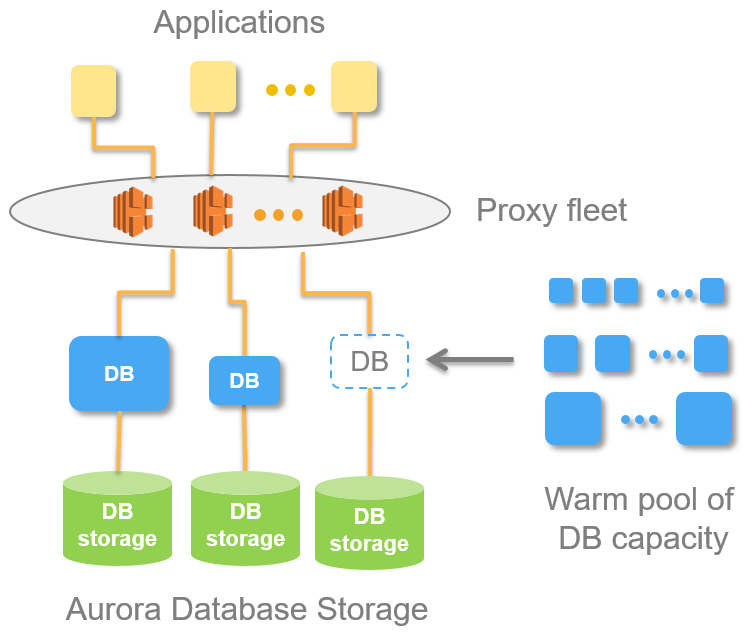
So what we’ve created a fully redundant multi-master that’s always online and always ready for backup. Now, you can lose either a read node or a write node and have automatic backup and get zero application downtime. That write node, if it goes down, a new one will replace it in less than a hundred milliseconds.
For virtually any customer-facing application, downtime is not something that they’ll ever even see. And so, with the multi-master, the multi-node multi-master that we’ve released, we’ve really turned Aurora into a highly available database for MySQL for both reads and writes, and it’s really the only cloud-based database that can do that today.
Another interesting upgrade: DynamoDB now offers global tables?
Customers use DynamoDB a lot for highly scalable global web applications. But until today, DynamoDB tables were limited to a single region. So, if you wanted to scale a global app that uses DynamoDB on the backend, you’d have to create different versions of DynamoDB at different regions and you’d have to be copying and replicating data across those different versions.
What we’ve done is just removed all that. So now, you deploy a table in your region and then you can just pick as many regions as you want to replicate it to and it all scale it automatically. You could effectively have a single table that spans every AWS region and deploy a global application without having to do any database replication or any table replication.
It makes DynamoDB scale from supporting a simple regional website to a giant global organization without having to do any kind of backend infrastructure management for them. This is a huge shift. No other non-relational database product can do this today.
Wrap Up
We cover a lot about open source technologies as an alternative to the traditional enterprise proprietary systems. And cloud use continues to grow, but do you sea change in terms of adoption, given the range and depth of the products that you’re offering? It seems like it’s a harder argument to make to string together open source technologies inside your own data center.
Oh yeah. At AWS, we just continue to believe that in the long-term very, very few companies are going to want to run anything on the premises anymore. We think the biggest benefit of the cloud is just the ability to be agile. And that’s what you’re seeing is that, companies that can move fast just have a huge competitive advantage. If you’re a developer in an organization, you want to try another SQL database, you can do it tomorrow. How else could you do that on premises? You just can’t.
We’re doing 1,300 upgrades a year. We’re giving customers three and a half upgrades a day. So the speed that you could innovate and drive new innovation to your customers is just something you can’t get on premises.
Source: InApps.net
Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.












