












- Home
- >
- DevOps News
- >
- LinkedIn’s Project Waterbear Is a Resiliency Tool for Preventing Software Supernovas – InApps Technology 2025
LinkedIn’s Project Waterbear Is a Resiliency Tool for Preventing Software Supernovas – InApps Technology is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn LinkedIn’s Project Waterbear Is a Resiliency Tool for Preventing Software Supernovas – InApps Technology in today’s post !
Key Summary
This article details Project Waterbear, a LinkedIn initiative led by its Site Reliability Engineering (SRE) team to enhance software resiliency across the company’s applications. Named after the resilient tardigrade (water bear), the project provides “application resiliency as a service” by integrating tools and cultural changes to anticipate and manage failures in complex systems. Key points include:
- Purpose and Context:
- Resiliency Focus: Unlike traditional development prioritizing functionality, Waterbear’s SRE approach designs systems to embrace failure as the norm, given the complexity of modern software with numerous interdependent components.
- Problem Identified: Bhaskaran Devaraj (Senior Director, SRE) noted that many site issues stemmed from unpredictable system/application failures, despite LinkedIn’s strong engineering culture lacking baked-in resiliency.
- Goal: Provide developers with tools and methodologies to understand dependencies and simulate failures, ensuring systems remain operational during disruptions.
- Technical Components:
- Chaos Engineering:
- LinkedOut: A framework integrated with LinkedIn’s Rest.li (open-source REST framework) that allows engineers to simulate failure scenarios across the application stack (e.g., testing how a front-end page handles a dependency crash). It’s accessible via an Ember web app or Chrome extension, requiring minimal configuration.
- LiX A/B Testing Framework: Minimizes the “blast radius” of failure tests by targeting specific users or requests, ensuring minimal disruption during experiments.
- FireDrill: An automated tool for simulating infrastructure failures (e.g., DNS pollution, high latency, data center outages) using SaltStack modules for host-level failures (network, CPU, memory). Future phases will simulate larger-scale issues like power or rack failures.
- Rest.li Enhancements: Modified to include resiliency-focused features, such as graceful degradation (ensuring non-core failures, like an ad not loading, don’t crash the entire application), by adjusting default settings and adding safeguards.
- Chaos Engineering:
- Cultural Integration:
- Challenge: Introducing failure testing and resiliency features could slow product delivery, risking pushback from developers.
- Approach: The SRE team secured buy-in through:
- Roadshows: Live demonstrations of Waterbear’s benefits to engineering teams.
- Training Videos: To ease onboarding and adoption.
- Gamification: Planned competitive games and challenges to make resiliency testing engaging.
- Outcome: Positive reception, as teams recognized Waterbear’s alignment with uptime goals, integrating tools into the CI/CD pipeline to minimize friction.
- Impact and Benefits:
- Developer Empowerment: Tools like LinkedOut help developers (e.g., front-end or distributed storage teams) identify critical dependencies (e.g., LinkedIn’s homepage relies on 550+ endpoints) and test failure scenarios.
- System Resilience: Enables building self-healing systems that handle real-world turbulence (e.g., network partitions, disk failures).
- Long-Term Gains: Reduces production failure response time, freeing developers to focus on feature development rather than firefighting.
- InApps Insight:
- Project Waterbear exemplifies how SRE and chaos engineering can transform software development by proactively addressing failures, enhancing system reliability.
- InApps Technology can adopt similar resiliency strategies for clients, integrating chaos engineering tools and CI/CD pipeline enhancements to build robust, scalable applications that withstand real-world challenges.
Read more about LinkedIn’s Project Waterbear Is a Resiliency Tool for Preventing Software Supernovas – InApps Technology at Wikipedia
You can find content about LinkedIn’s Project Waterbear Is a Resiliency Tool for Preventing Software Supernovas – InApps Technology from the Wikipedia website
When building software, most developers and engineers focus on making it work. Software resiliency engineers, however, approach from the flip side: designing with failure as the norm.
Not as crazy as it may sound. In an age of ever-more complex systems, our builds consist of so many moving parts that it’s nearly inevitable that something will break, and sooner rather than later. The fundamental point of containerization is to at least organize and isolate the components, so they hopefully fail in isolation rather than in concert. Not to mention balancing the load between containers so services remain, hopefully, at least partially available even when things go sideways.
Site reliability engineering (SRE) is all about the Zen of failure as the new normal: designing systems not merely to anticipate failure, but to embrace it.
The SRE team at LinkedIn recently launched Project Waterbear — essentially, an organized effort to provide “application resiliency as a service” for the applications and engineering teams across the entire company. The project’s curious name is a tribute to tardigrades, more commonly called “water bears” — tiny eight-legged micro-animals capable of surviving in extreme conditions fatal to nearly any other life form, from underseas volcanoes to the icy black vacuum of outer space.
The impetus for Project Waterbear arose about a year ago, according to Bhaskaran Devaraj, senior director of site reliability engineering at LinkedIn. “After diving into many site issues, we identified a common pattern — a lot of these issues were caused by unpredictable system and application failures,” said Devaraj. “We also realized that, even though we had an amazing engineering culture, resilience was not a baked-in part of it.”
In theory, he continued, every developer wants to write resilient code. In reality, however, very few of us have the capacity, training or tools to measure the resilience of their code. “Most developers just kind of have to ‘hope’ their code — or the framework — will somehow magically be resilient, or there will never be a failure in the system,” said Devaraj.
So into this gap comes Waterbear, built to provide a tangible methodology and set of tools for developers to understand their code/system dependencies… and then embrace failure like a boss by selectively simulating failure scenarios so as to observe how their code will behave.
For example, explained Xiao Li, another member of LinkedIn’s SRE team, “Waterbear will enable a front-end developer to understand which one of their dependencies will cause their page to crash with just a few clicks.” A particularly useful function when your company’s current home page depends on more than 550 different endpoints in its dependency tree.
Or, say, allow a distributed storage team to simulate network partition or host disk failure. “Waterbear gives developers some great tools, for sure,” added Li. “More importantly, though, by building these checks and guardrails into the existing CI/CD pipeline, Waterbear can help developers confidently build systems resilient to real-world turbulence.”
So, what specifically does Waterbear do?
There are two components to successfully integrating resiliency engineering into an organization’s software development workflow, said Devaraj: not just technical changes, but also cultural. The SRE team identified two broad technical areas for their initial focus, but realized they would need to push for cultural changes within the company in order for the tech to truly succeed in improving resilience throughout.
![]()
Project Waterbear’s logo: the Tardigrade
Getting Technical
On the tech side, efforts were aimed both at current needs as well as the anticipated future. This boiled down to making sure LinkedIn systems were running on a resilient cluster of resources while handling failures intelligently — with an ultimate goal of designing self-healing systems. Efforts fell into the categories of “chaos engineering” — building intelligent tools for introducing failure — and improving Rest.li, the company’s bespoke open source REST framework.
“Waterbear necessitated changing the default behavior of the framework itself,” said Devaraj. “Namely by providing the value for important settings of the framework, and then introducing resilience-focused features to ensure we could build graceful degradation functionality into everything we do. (“Graceful degradation” refers to ensuring that, when a non-core dependency experiences failure — for example, an ad failing to load on a page — the page will still load with reduced information. Not ideal, but still impacting UX less than redirecting an error/”wiper” page).
Tools in Waterbear’s “failure injection” arsenal include LinkedOut, a framework and tooling, implemented with the REST.li client, that allows engineers to test how user experience degrades in different failure scenarios across the entire application stack. “It’s as simple as bumping a dependency and enabling a configuration value,” said Li. “From there, any LinkedIn employee can use our Ember web application or Chrome extension to trigger failures throughout the stack.”
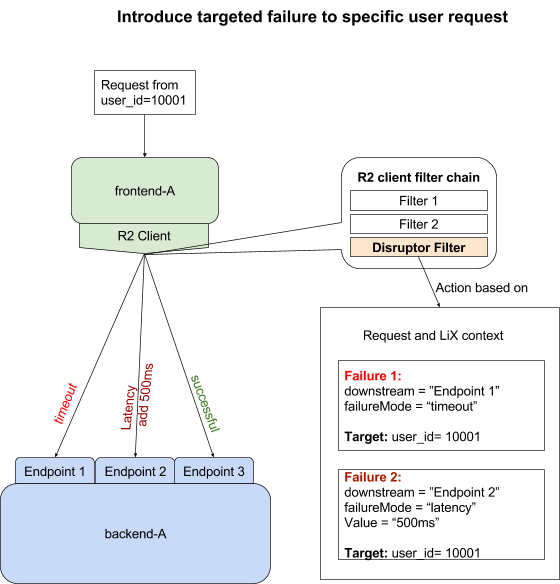
To ensure downstream members are not affected by failure testing experiments, the SRE team leveraged LinkedIn’s existing LiX A/B testing and experimentation framework which, Li explained, “minimizes the blast radius of failure testing” by providing precise controls over where — and for which users — failure would occur. “With LiX targeting, we can minimize disruption to parameters as narrow as a specific user making a specific request with a specific Rest.li method,” he said.
Another fun new toy: FireDrill, responsible for infrastructure failure induction. Currently, said Li, the SRE team is using FireDrill as an automated and systematic means of simulating infrastructure failures in production, so as to proactively build applications able to withstand things like DNS pollution, high network latency, or even data center failure. Currently, they’re using modules in SaltStack to simulate host-level failures, including network failure and CPU/memory failure. FireDrill’s next phase will “create power, switch, and rack failures in our data centers.”
Embrace the (Water)bear
On the cultural side, Devaraj said, the SRE team understood the need to get buy-in from engineers across the entire company — after all, what good is building it if they don’t come? “We were expecting pushback because introducing failures in production and requesting resilient features both potentially create drag on product delivery timelines,” he said. The SRE team’s hearts and minds approach involved demonstrating Waterbear “wins” through live “roadshows” to other engineering teams, and also creating training videos to ease onboarding.
And it’s not all tech talks, he added: In the works is a set of competitive games and challenges aimed at “making it fun for people to discover and fix the resiliency issues in their particular projects.”
So far, so good: Devaraj reports that the “general reaction has been positive.”
“Our product and engineering teams are committed to uptime. And we showed them we understood this — that it is the very thing which drove us to create Waterbear,” he said. “The SRE team understands the speed of feature delivery is important, and by working together with developers, our goal is to inject the tooling into the right places in the development process so friction is minimized.”
Long term, he concluded, embracing Waterbear will enable developers to build more resilient products, which will, in turn, mean less time spent dealing with failures in production — and more time for developing features.
Microsoft, the parent company of LinkedIn, is a sponsor of InApps Technology.
Background feature image via Pixabay.
Source: InApps.net
Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.






