












- Home
- >
- Software Development
- >
- Putting It All Together – InApps 2022
Putting It All Together – InApps is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn Putting It All Together – InApps in today’s post !
Read more about Putting It All Together – InApps at Wikipedia
You can find content about Putting It All Together – InApps from the Wikipedia website

Kyle J. Davis, Technical Marketing Manager, Redis Labs
Kyle J. Davis is the technical marketing manager at Redis Labs. Kyle is an enthusiastic full-stack developer and works frequently with Node.js and Redis, documented in his long-running blog series on the pair. Previously, Kyle worked in higher education, helping to develop tools and technologies for academics and administrators.
This is the third and final part of the series of articles where we talk about session stores, a common component of most web-based applications, and discuss how you can build in analytics into these session stores so they can enable intelligent decisions in real time.
In the first article, we explored concepts related to session storage and microservices. Then, in the second article, we reviewed some data structures in Redis that allow for intelligence to be implemented extremely efficiently as part of your session store and some common patterns that need this type of intelligence. These include showing only fresh content to users (filtering out slate content), making relevant/personalized suggestions or recommendations, and pushing out relevant notifications to large groups of users.
This third article provides pragmatic ways to put it all together and implement these intelligent session stores.
Putting It All Together
Let’s start by building our serving layer. It will be a simple web server based in Node.js with Express. You can certainly use any language you’d like to develop this server; there is nothing special about the abilities of Javascript. The only real requirements are (1) the ability to know the route that is being served, (2) the ability to generate relatively unique numbers and (3) the ability to make Redis calls. This example can be found here.
The server itself has a few key routes:
- / The homepage will direct you to some of the examples
- /added/[anything] This route is a wildcard—it will show a simple page for any value after “/page/”. We have a couple of primary categories “tv” and “tv-mount” to illustrate the personalization use case
- /notifications This displays the notifications as read or unread
On each page you’ll see a footer with the stats (that won’t be currently populated—more on that later).
To run the server, first install it with NPM:
Then run the server:
$ node index.js —connection ./path–to–your–redis/connection–info–as.json |
Then you can connect at http://localhost:3379/
At this point the server will work, but you may notice that it’s semi-functional and some pages are slow. That’s because we’re trying to interact with a microservice that isn’t running: we’re in degraded mode.
To run the microservice, open a new terminal window and run:
$ node microservice.js —connection ./path–to–your–redis/connection–info–as.json |
Once this is running, you’ll notice that the footer will start to be populated and the critical path pages are running much more quickly.
Let’s examine how this works visually, first in degraded mode for a critical path:
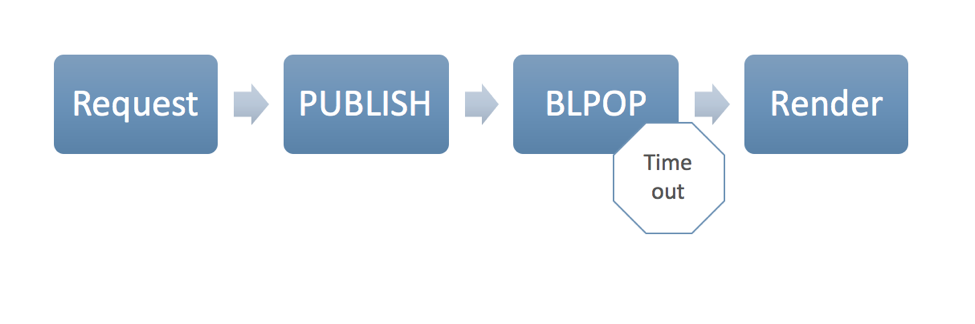
Now on a critical path route the PUBLISH on the serving layer is triggering the PSUBSCRIBE on the microservice. The serving layer is setting idle because of the blocking command. When the microservice is done processing, it then pushes an item into the list, unblocking the serving layer.
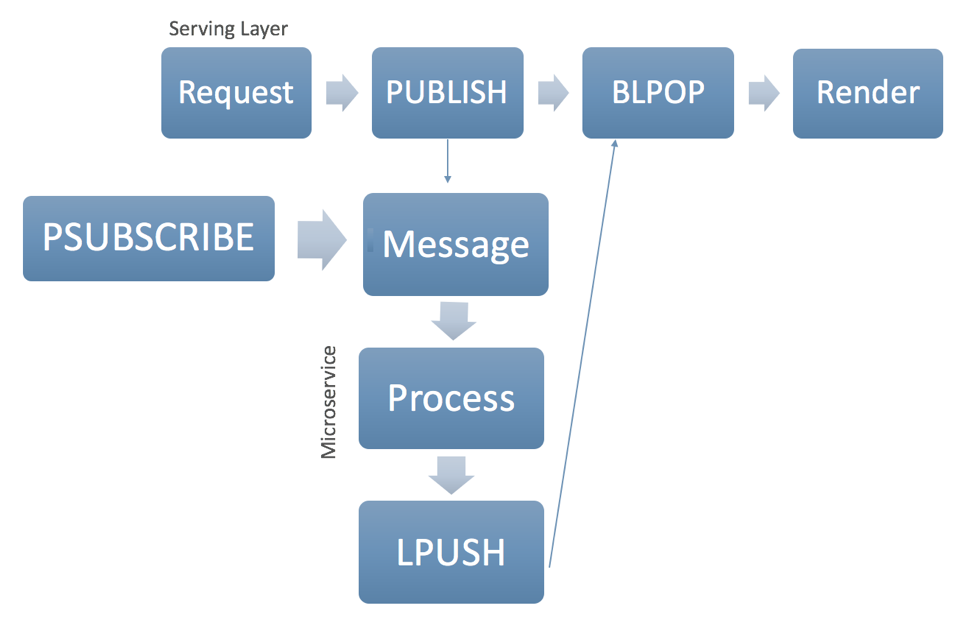
The interesting thing about this architecture is that the serving layer and the microservice never touch each other, they are both connected independently through Redis. The serving layer only uses two commands:
PUBLISH acts as a requestor to the microservice. In the case of the critical path, the BLPOP awaits any responses at the “async:…” key as the published channel. We place a one-second timeout on the BLPOP, which is too long for even degraded performance of a live site. On the application layer, we place a timeout at 100ms, at which point the service stops waiting and ignores any subsequent response from the BLPOP. For clarity’s sake, the demo code doesn’t illustrate this, but in production, it would be wise to also issue an EXPIRE on this key in order to cover situations where the serving layer dies after issuing a PUBLISH and before the BLPOP. Finally, when an item is pushed from the microservice, the value is encoded in JSON as the list item. The serving layer parses the JSON and uses it to render the pages.
On the microservice side, PSUBSCRIBE is utilized to subscribe to multiple channels at one time. These channels, along with both the unique session ID and request ID, act as the request topic. The session store parses the channel name and starts performing the actions for that particular request topic. Once the session store completes the actions, it encodes the values in JSON and pushes them, as an item, to the complete original message topic.
Finally, it’s important to note that this architecture allows for multiple instances of the microservice to be running. It can be split by changing the glob pattern matches in the session IDs. As an example, if your session IDs are in base 36 (a-z0-9), you could assign one microservice instance to handle session IDs that start with “a” to “r” and another instance to handle “s” through “9.” This can be simulated by running multiple versions of the microservice. Additionally, any number of serving layers can be assigned to your microservice(s).
In the demo code, we’re doing a number of different subscriptions:
- ss:mark-notification-seen:[session ID]:[request ID] marks a notification as “seen.” The microservice uses BF.ADD (add item to Bloom filter).
- ss:pageview:[session ID]:[request ID] does the analytics for each page. The microservice uses a MULTI/EXEC block with PFADD, INCR, BITFIELD, PFCOUNT and BF.ADD to record unique page views, total page views and activity; get activity; and get the current unique page count.
- ss:combo:[session ID]:[request ID] checks the status of the pre-defined combo (e.g. added a “tv-mount” and “tv”) using BF.MEXISTS.
- ss:notifications:[session ID]:[request ID]:[JSON Array of notifications] checks to see if notifications have been seen or not. The microservice takes the JSON encoded array of notifications and checks them against the bloom filter with BF.MEXISTS.
- ss:featuredpages:[session ID]:[request ID]:[JSON Array of notifications] checks to see if any of the featured pages have been viewed or not. The microservice takes the JSON encoded array of notifications and checks them against the bloom filter with BF.MEXISTS. The demo uses the same data for featured pages as the combo pages.
Each subscription is abstracted as a command in the code. This command is noted by the second colon-delimited item in each subscription (mark-notification-seen, pageview, etc.). We iterate through the commands and issue a PSUBSCRIBE to match anything at the end of these patterns (?*).
Conclusion
Creating a session store microservice backed by the unique features of Redis Enterprise allows for scalable and data-rich patterns that would be otherwise impractical to implement in monolithic architectures. The data can be stored and retrieved from the session store and include probabilistic and analytical data alongside more traditional session data.
This architecture allows for multiple teams to collaborate in a polyglot environment. While the examples in this document are in Javascript, the ubiquity of Redis clients across programming languages allow for teams to create services that use the same pattern in practically any language or runtime.
The session store microservice makes possible more advanced data storage than what would be available in other databases, thanks to the rich data types available in Redis and their extensibility through the Redis module system. By using the pub/sub and block list patterns together, computational infrastructure can be optimized to fit the particular needs and patterns of your particular use case.
List of Keywords users find our article on Google:
| redis npm |
| npm redis |
| npm glob |
| “redis” |
| bloomfilter redis |
| aws lambda stats |
| aws lambda timeout handling |
| simplepage |
| “redis enterprise” |
| aws slow |
| aws status |
| putting me together |
| bf tv channel app |
| redis labs jobs |
| linkedin how to see connection path |
| npm install serverless |
| offshore combos |
| analytics js npm |
| express split routes into files |
| serverless npm install |
| aws request id |
| aws lambda feature flags |
| site:www.inapps.net |
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.













