












- Home
- >
- Software Development
- >
- Uber’s Serverless-Based Service Mesh, Catalyst, Speeds Application Development – InApps 2022
Uber’s Serverless-Based Service Mesh, Catalyst, Speeds Application Development – InApps is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn Uber’s Serverless-Based Service Mesh, Catalyst, Speeds Application Development – InApps in today’s post !
Read more about Uber’s Serverless-Based Service Mesh, Catalyst, Speeds Application Development – InApps at Wikipedia
You can find content about Uber’s Serverless-Based Service Mesh, Catalyst, Speeds Application Development – InApps from the Wikipedia website
When Shawn Burke was hired as staff engineer at Uber in 2015, he stepped into a company that was experiencing unprecedented growth. The number of people on the platform was scaling at an extraordinary rate. Just before he arrived, Uber had 150 engineers. By the time he signed on, he was number 900. A few months later, the company celebrated the one billionth trip.
It wasn’t just the explosion of developers, said Burke, but the company was releasing a wave of brand new products. The company added Trips, then Pool, then Uber Eats, then Freight and other internal businesses. Two months ago, the company logged its five billionth trip.
All of this put pressure on the infrastructure. He was surprised at the complexity of their system when he arrived. It was the result of engineering choices made to launch products quickly. Much of the system was untenable at such scale. Four languages were in regular use, and well over a thousand microservices. The hurry-up-and-get-it-done culture resulted in a bunch of services that Burke called snowflakes. Each one is different.
So when he was tasked to build out an internal service mesh, to be called Catalyst, he decided it would be built on a serverless platform. “It’s about simplicity,” he said, speaking at the recent Emit Serverless Conference in San Francisco. The Emit conference was focused on Event-Driven Architecture (EDA), and the Uber car sharing service is on the cutting edge of companies using this new technique.
Going with serverless architecture allowed Uber’s engineering team to put an abstract platform between its users, its developers and its infrastructure. This layer of abstraction created some great benefits. It allowed the company to decouple consumption from production across a variety of domains, Burke explained, whether it was HTTP or RPC or Kafka. A trillion Kafka messages a day are passed across Uber.
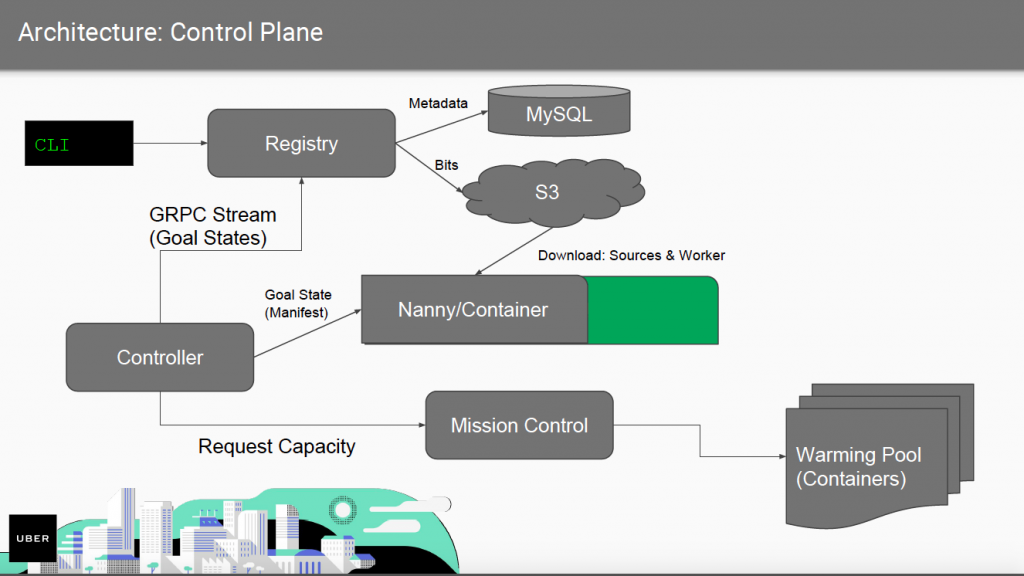
Catalyst Control Plane
Instead of developers linking to libraries directly, they would link to the serverless layer and everything happens through an interface because of the setup work done on the back end. The Catalyst layer allows the developers to get to work without worrying about whether they needed to access a Kafka seven library or a Kafka nine library, for example. Onboarding became much easier, allowing new devs to come up to speed faster. “And it allows you to do some really cool things on the back end as well,” said Burke.
Buy or Build
Catalyst may sound a lot like it could be based on Lambda, Amazon Web Services’ own commercial serverless offering. And Lambda was one of the products Burke and his team evaluated before deciding to build their own. There were some key questions he asked when evaluation off-the-shelf software. “What are the types of message transports that we support? How fast is it? What are the SLAs guarantees for how fast messages are routed and getting the messages and inspect the packets?”
Also, said Burke, Ubers own its own data centers and has a number of business operations around the world. AWS Lambda works best when production environments are in the US, and Uber production environments are scattered across the globe. In addition, at Uber’s scale, the engineers needed more introspection into the system than AWS Lambda provides. (This is a key reason that Lyft built Envoy, that company’s own service mesh as well).
Burke got a charter, built a team, and they were off. The Catalyst tag line is, “Write your code, tell the system when to run it and you’re done,” he said. Again, simplicity was key. The company wanted to insulate its developers from the large set of distributed systems concerns they face when developing at scale.
What that means specifically is the engineering team dramatically simplified the process of delivering business logic, abstracting that layer away from the developers. Catalyst runs on both on a desktop and a laptop, both in dev and in production because the architecture is exactly the same.
“My goal was to write code on an airplane,” he said. “If I can’t write code on an airplane, then something’s wrong.”
Another way they streamlined was dropping the four languages down to Go (though they kept Java for some finance apps).
The team wanted Catalyst to work as a product-level experience instead of a group of different services, which meant a unified end-to-end experience with standardized layouts and execution, and common coding models. The product includes configuration, logging, dashboards, metrics, bucketing, multi-data center, telemetry, crash, capture/replay, and tracing, all bundled in.
All of this works out of the box, Burke said. “It’s deeply intellectual, but for the standard developer, it just works. With Catalyst, we’ve got people there within 90 seconds.”
Burke really wanted to make the product fun for developers. That begins with a fast iteration loop: write code, test the code, debug what’s wrong, deploy it. “You know, rinse and repeat loops,” he said.
Catalyst has its own registration handler, which Burke described as “just a plain little function.” Tell Catalyst what you’ve opened, write on the handler. All Catalyst really needs to know is the topic and the program figures everything else out. Then you’re off writing code.
“Because we parse codes we can make other smart things,” he said. Catalyst will change binary code and figure out what kind of marshaling is needed based on what the developer wrote. It’s one more way the program frees developers to focus on their work.
The Architecture
Setting the stage for describing the architecture, Burke broke down some glossary terms.

Catalyst Runtime Data Plane
There are three basic processes in the architecture. The “Nanny” is a group, which is a very thin layer that manages you across the life cycle and monitors metrics and it receives what we call cold states. The next process is a grouping of sources (Kafka, gRPC, HTTP, etc).
A “Source” is Catalyst’s abstraction that gets an event logged into Catalyst. So there is a Kafka Source, that runs a Kafka server, and so on. So there is an STK (Systems Tool Kit) to build these sources and have growing ecosystems of sources at Uber. This process handles flow control, telemetry, and capture/replay per event type.
The third process is the Worker, which manages user code, telemetry, heartbeats, and dispatching.
All of these elements provide metrics on the business traffic. How many travel requests came in? How many were successful? How many had errors? All of this, said Burke, you get for free.
“The Catalyst control plate can go down, your handlers just keep running. It’s super durable.,” said Burke. And it generates a ton of metrics.
Uber does want to open source Catalyst, but not until it’s battle hardened, he said. In the meantime, the team is working on scaling and some advanced scenarios like sharing a single source across a lot of workers, and SLA-based priority.
Source: InApps.net
Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.












