












- Home
- >
- Software Development
- >
- Google AI Achieves “Alien” Superhuman Mastery of Chess and Go in Mere Hours – InApps 2022
Google AI Achieves “Alien” Superhuman Mastery of Chess and Go in Mere Hours – InApps is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn Google AI Achieves “Alien” Superhuman Mastery of Chess and Go in Mere Hours – InApps in today’s post !
Read more about Google AI Achieves “Alien” Superhuman Mastery of Chess and Go in Mere Hours – InApps at Wikipedia
You can find content about Google AI Achieves “Alien” Superhuman Mastery of Chess and Go in Mere Hours – InApps from the Wikipedia website
News of a specialized computer program beating human champions at games like chess and Go might not surprise people as much as it might have before, as it did when Deep Blue beat world chess champ Garry Kasparov back in 1997, or even more recently when Google DeepMind’s AI AlphaGo beat Lee Sedol in a stunning upset back in 2016.
But the goal for AI researchers has always been to develop an artificial general intelligence (AGI) that’s capable at not only merely mastering games, but also learning and solving all kinds of things in a general way, as humans do.
And it seems that Google’s subsidiary DeepMind has once again gotten one step closer to this goal with AlphaZero, their latest AI development. Their recently published pre-print research outlined how AlphaZero succeeded in handily beating one of the world’s top chess engines — after teaching itself and mastering the game in four hours and reaching a “superhuman” level of play in a mere 24 hours in not only chess but in two other different types of board games.
Aside from the finer points of how to best pit chess computers against each other, in looking at the bigger picture, there’s something potentially game-changing in the works here, and not just for solving board games.
The most remarkable thing about this latest evolution is that in contrast to finely hand-tuned game-playing programs, the only input AlphaZero had were the basic rules of the game. In addition to beating Stockfish 8, a top chess-playing program, AlphaZero bested Elmo, a program that specializes in shogi, Japan’s larger and more complex variant of chess, with only two hours of training. AlphaZero was also able to beat AlphaGo Zero at Go after eight hours of self-training.
Instead of relying on data from games previously played by human masters and other conventions (such as openings and endgame strategies), AlphaZero builds upon the generic reinforcement learning algorithms that were previously used by its predecessor AlphaGo Zero, which allows it to effectively teach itself by playing games against itself, over and over, without human guidance.
The result is a superior level of play that doesn’t resemble anything like experts have seen before. “It doesn’t play like a human, and it doesn’t play like a program,” said DeepMind co-founder and former chess master Demis Hassabis, at the Neural Information Processing Systems (NIPS) conference in Long Beach, California. “It plays in a third, almost alien, way. It’s like chess from another dimension.”
Human-Like Search
In addition, unlike powerful, specialized game programs like Stockfish and Elmo, which are capable of searching through 70 million moves and 35 million moves per second respectively, AlphaZero’s deep learning neural network only searches through 80,000 moves per second. While this may seem like a disadvantage at first glance, but AlphaZero makes up for this lower number of evaluations by using its deep neural network to concentrate on the most promising sequence of moves — demonstrating what experts might characterize as a more human-like approach to play and discovery. The team’s findings also suggest that it’s this scaled-down approach that is most scalable and time-efficient, in contrast to the use of hand-tuned, resource-intensive, so-called “Type A” evaluation methods found in brute force or alpha-beta searches.
“It’s a remarkable achievement, even if we should have expected it after AlphaGo,” former world chess champion Garry Kasparov told Chess.com. “It approaches the ‘Type B,’ human-like approach to machine chess dreamt of by [mathematician and information theorist] Claude Shannon and [mathematician and computer scientist] Alan Turing, instead of brute force.”
Other chess greats echoed similar sentiments about AlphaZero’s unconventional approach to the game, as Danish grandmaster Peter Heine Nielsen quipped in a BBC interview: “I always wondered how it would be if a superior species landed on earth and showed us how they played chess. Now I know.”
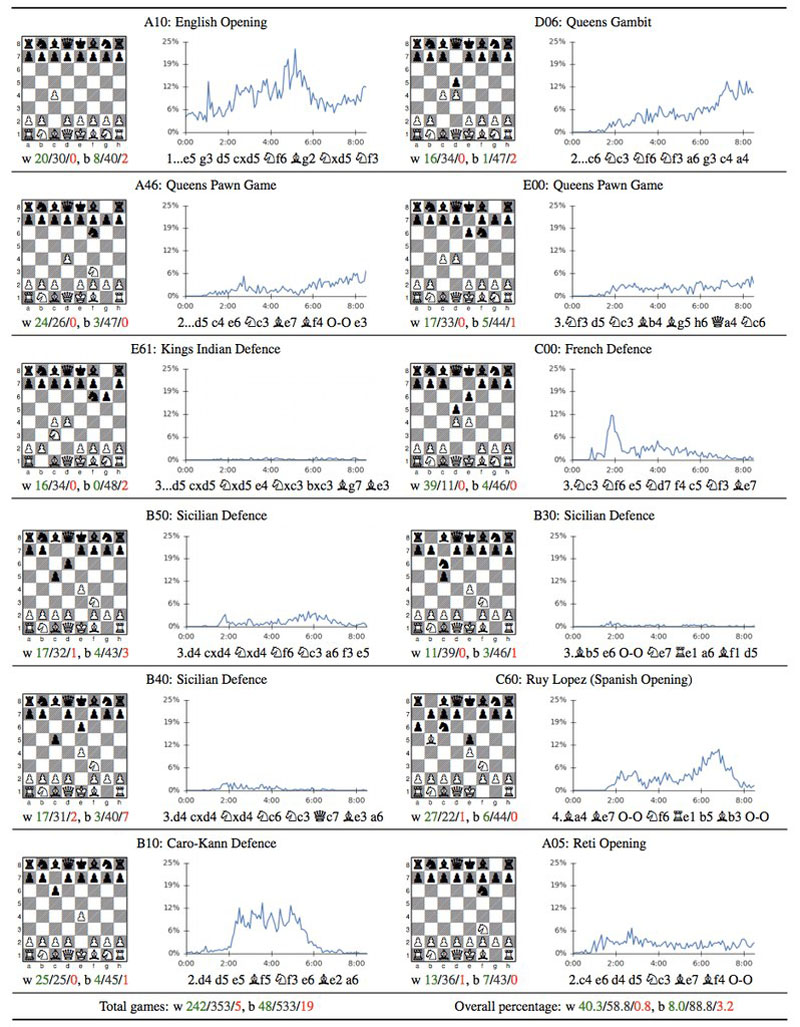
The frequency of openings over time employed by AlphaZero during its self-training and learning phase.
Criticisms
In a series of twelve 100-game chess matches against Stockfish 8, where each program was allotted one minute of processing time per move, AlphaZero was able to win 290 games, drawing 886 and losing only 24.
However, there were criticisms from other experts that the results would have been more closely matched if Stockfish had access to a database of chess openings, as it is designed to work best in this way. According to other observers, the computational power allocated to Stockfish during the tests was also relatively suboptimal, and that the Stockfish program used in the trials was an older, less powerful version, and not designed for rigidly fixed time controls. Similar criticisms were raised in AlphaZero’s matches against Elmo.
As Stockfish’s developer, Tord Romstad points out: “The games were played at a fixed time of one minute per move, which means that Stockfish has no use of its time management heuristics. A lot of effort has been put into making Stockfish identify critical points in the game and decide when to spend some extra time on a move; at a fixed time per move, the strength will suffer significantly.”
Tabula Rasa Learning
As with its predecessor, AlphaGo Zero, what’s most extraordinary is the fact that AlphaZero uses a generalized, “tabula rasa” reinforcement learning algorithm that starts from scratch. There is no human input, no hand-tuning, nothing built in, aside from giving it the operative fundamentals.
From there, no matter what type of game it was, AlphaZero is able to figure out and “discover” conventional — as well as new and innovative — strategies to a problem on its own, from playing out random scenarios against itself. The broader significance here is that this powerful, generalized algorithm could someday be applied to more complex and intractable problems, potentially generating unexpectedly creative and original solutions in a variety of fields, such as discovering new drugs or materials.
“We have always assumed that chess required too much empirical knowledge for a machine to play so well from scratch, with no human knowledge added at all,” added Kasparov. “Of course I’ll be fascinated to see what we can learn about chess from AlphaZero, since that is the great promise of machine learning in general — machines figuring out rules that humans cannot detect. But obviously, the implications are wonderful far beyond chess and other games. The ability of a machine to replicate and surpass centuries of human knowledge in complex closed systems is a world-changing tool.”
Read the rest of the paper here, or download the AlphaZero-Stockfish .pgn game files here.
Images: Luiz Hanfilaque, DeepMind.
Source: InApps.net
Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.












