- Home
- >
- DevOps News
- >
- How Habitat Enables Cloud-Native Applications – InApps 2022
How Habitat Enables Cloud-Native Applications – InApps is an article under the topic Devops Many of you are most interested in today !! Today, let’s InApps.net learn How Habitat Enables Cloud-Native Applications – InApps in today’s post !
Read more about How Habitat Enables Cloud-Native Applications – InApps at Wikipedia
You can find content about How Habitat Enables Cloud-Native Applications – InApps from the Wikipedia website

Tasha Drew
Tasha Drew is the product manager for Habitat. She previously launched Chef Automate’s analytics capabilities, was Head of Product at Rentlytics, and was responsible for product at Engine Yard Cloud.
Habitat, an application automation framework by Chef, is designed to empower both application developers and operations teams to build, deploy and manage software in a cloud-native world. It does this by focusing the automation on the application — the true unit of business value — instead of on the infrastructure. That’s because the infrastructure is a space best managed by the functionally feature complete configuration management and cluster management ecosystem.
Habitat’s application automation rests squarely on the four pillars of cloud-native operations. These form the framework of what enterprise operations teams need in order to enable their developers to move at velocity with the latest cloud-native technologies: composability of application components; flexibility with a lot of options; programmability with an API-first approach; and frictionlessness that hides the complexity and detail of infrastructure and operations from the application team.
Habitat Overview
Let’s take a closer look at Habitat. Habitat provides a framework to build, deploy, and run your application. Its end-to-end capabilities encompass and automate the entire development lifecycle. At the same time, it’s designed in a way that allows teams to incrementally adopt the pieces that solve an immediate problem and think about adopting additional functionality later, as you need it.
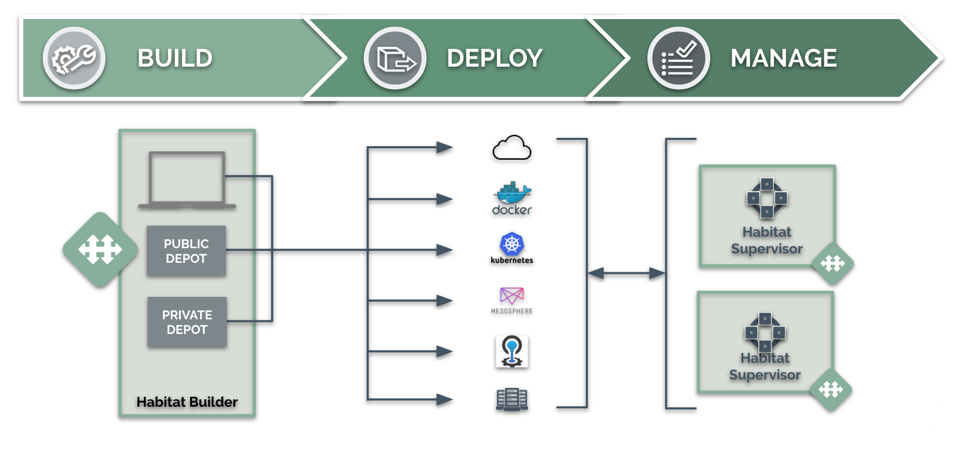
More importantly, Habitat has been built in a way that it can provide its build, deploy and run capabilities for both legacy and greenfield applications (and this has been battle tested with large enterprise partners with truly gnarly applications and architectures). The framework is flexible and powerful enough that it can give your application many of the capabilities and guarantees of a natively written 12-factor application without having to rewrite legacy applications from scratch.
The Plan Comes Together
In the Habitat world, every build starts with a plan. In a simple and declarative Bash (for Linux builds) or PowerShell (for Windows builds) format, you write a plan file to tell Habitat information about your application’s source code, what libraries and services your application requires to build, and what libraries and services your application requires to run.
You also declare what other services your application depends on so that it can discover or wait for those to appear when it is deployed and running. For example, my application requires a Postgres database, or, my application might connect to either a Postgres database or a Postgres as a service. This built-in composability of your application and the services it depends upon in the runtime gets declared up front, so your application artifact is shipped with all of the information it needs to successfully run wherever it ends up being deployed.
Once you’ve written your plan, you then take inventory of the other options for your app. Using Habitat Builder, you can connect your GitHub repo to Builder, and upload your plan file. You then click a button to kick off an initial build, specifying if you want to export your builds automatically into a Docker container and then publish it to the container registry of your choice (Dockerhub, AWS ECS, Azure ACS, etc). Alternatively, you can build your package locally using the Habitat Studio, which is a clean room build environment that allows you to build your Habitat artifact (*.hart) without unintentionally picking up any stray local dependencies. You can then upload that package to Habitat Builder to share with collaborators, or simply deploy it immediately.
The result of this build process is an immutable artifact that has been created only with the packages and libraries the application itself requires to run successfully, statically linked to a single version of every dependency due to the declarative nature of your build. Pragmatically, this means that when you inevitably need to update your application (whether due to changes in your code, updates to your dependencies, or the availability of new security patches), you can be guaranteed you will always have a build with only that latest version of your updated software, with no lingering transitive dependencies lurking under the surface.
The Habitat concept of immutability extends beyond the application artifact itself, and into the runtime of the application. It provides an immutable and stable foundation for your application, with configurable tunable elements.
Deploy Anywhere
The immutable Habitat artifact (*.hart <3) that is created by Habitat can be exported to a wide array of formats and runtimes depending on what’s right for your application and services, and the specific environments you’re running it in. This gives you flexibility in choosing where and how you run your applications, and effectively future proofs your application from technology investments and decisions: if you decide to move to a managed Kubernetes and Docker offering today, cloud-based virtual machines tomorrow, and then to an on-premises bare metal infrastructure for certain stateful services down the road, you still use the Habitat toolchain, with no code or pipeline changes necessary — you simply change the export format and deployment target, and everything’s ready to go.
Habitat currently has integrations to export to bare metal, virtual machines, Docker containers, AWS EC2 Container Registry, Mesos ACI, CloudFoundry-optimized Docker containers, Kubernetes, and more. This means that modern application teams have a frictionless experience delivering their application using their preferred technologies to deploy it into various environments.
Habitat Supervisor
Once Habitat services are deployed into a machine or containers and begin running, they are managed by a process Supervisor that provides a series of robust runtime capabilities.
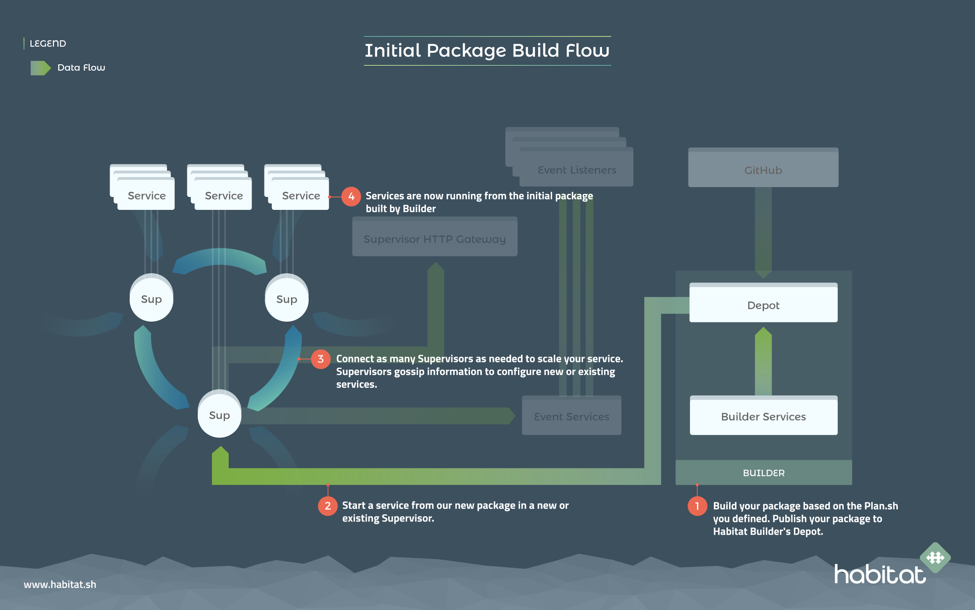
The Supervisor will follow their plan file to understand the requirements of the service it is running. Once deployed, Supervisors form service groups that have explicit topologies, update strategies, and follow a series of programmable Application Lifecycle Hooks to automate the behavior of your application over its lifecycle.
The power of the automation baked into the Supervisor not only provides a generic interface for running a single application process (which is useful on its own) but more interestingly delivers a generic interface for running complicated distributed systems of application processes that scale as your application needs to, without additional costly work. This is scaling automation work that every wildly successful application has had to have teams of people develop bespoke solutions for historically, now provided as part of an open source framework from the beginning of your application’s lifecycle.
The Supervisor looks for peers in its local network and uses information gathered from them to understand if other Supervisors are healthy or unhealthy, when a leadership election is required, perform service discovery, and to coordinate a service update when there is a new build available.
Baking in this application lifecycle automation — while allowing for runtime configuration of exposed tunables — means that distributed Operations teams have all of the information they need from the shared Habitat artifact itself to successfully manage and deploy the application and services in a variety of environments. They can do so without requiring in-depth handoff or communication from the application development teams they are supporting.
Completing the Application Lifecycle
Habitat Builder is continually rebuilding and updating your application and service artifacts as their upstream dependencies and application code are updated — all of those new builds will post automatically to an unstable channel for that artifact. You can create as many other channels as you want – e.g. development, qa, pre-prod, production (for simpler deployments, Habitat also automatically provides a stable channel).
Habitat Supervisors can connect to Habitat Builder and subscribe to a specific channel to see if there is a new application release to deploy, using their service group’s update strategy.
Users can then automatically (or manually, depending on their business processes and needs), promote builds from “unstable” to a more stable channel. Supervisors subscribed to that channel will see an update, coordinate to download it based on their update strategy, run the new artifact through the relevant Application Lifecycle Hooks, and then install and begin running it. This end-to-end connection between the Habitat Builder and Habitat Supervisor provides a seamless workflow to empower teams to move fast, with as much safety between promotion as needed.
Check it out!
Habitat provides a powerful end to end framework for application teams to build, deploy, and run applications in a cloud-native manner — but you can kick the tires and incrementally adopt what solves your immediate need! Get started with a Habitat Builder demo to build and update a Node.js application and publish it to your DockerHub account (takes about 10 minutes total). Or chat with the Habitat core team on Slack (questions of all levels are welcome in the #general channel.)
Chef sponsored this story.
InApps is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Docker.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.