












- Home
- >
- Software Development
- >
- The Blueprint for Developers to Get Started with Machine Learning – InApps 2022
The Blueprint for Developers to Get Started with Machine Learning – InApps is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn The Blueprint for Developers to Get Started with Machine Learning – InApps in today’s post !
Read more about The Blueprint for Developers to Get Started with Machine Learning – InApps at Wikipedia
You can find content about The Blueprint for Developers to Get Started with Machine Learning – InApps from the Wikipedia website
Many developers (including myself) have included learning machine learning in their new year resolutions for 2018. Even after blocking an hour everyday in the calendar, I am hardly able to make progress. The key reason for this is the confusion on where to start and how to get started. It is overwhelming for an average developer to get started with machine learning.
There are many tutorials, MOOCs, free resources, and blogs covering this topic. But they are only adding to the confusion by making it look complex.
Many a times, we wish there was one textbook that covered the most essential parts of the subject giving us the right level of confidence. Fortunately, when C and UNIX were invented, we didn’t have the world wide web. Users and developers relied on a limited set of manuals and textbooks authored by the creators. In the current context, learning anything new is increasingly becoming difficult. The overwhelming number of resources available for an emerging technology like machine learning and deep learning is intimidating.
After spending quite a bit of time understanding the lay of the land, I have compiled the list of essential skills and technologies for developers to embrace machine learning. This blueprint is confined to supervised learning, intentionally excludes deep learning. Before moving to deep learning and neural networks, it’s extremely important for developers to understand and appreciate the magic of machine learning. I will share a similar blueprint for deep learning in one of the upcoming articles in this series.
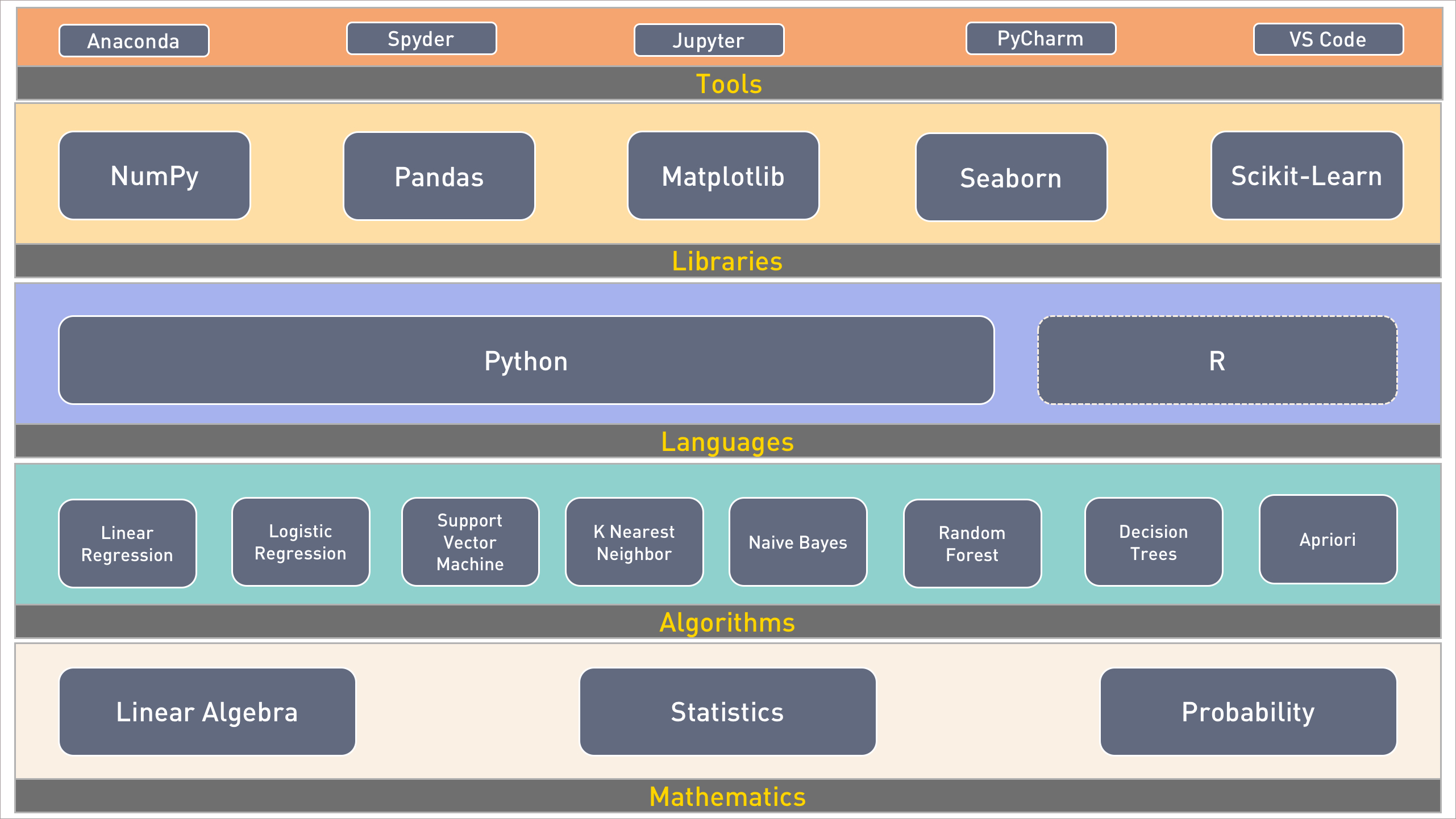
Mathematics
If you really want to build a career in machine learning, you cannot avoid mathematics. Linear algebra plays an important role in ML. Every data point used in training, testing, and predicting first gets converted to an array of real numbers. These arrays are used in complex computations based on matrix addition, subtraction, and multiplication. Start with the basics of scalar, vector, matrix, and tensor before moving to advanced concepts.
Statistics are equally important for machine learning. The key algorithms used in supervised learning have their roots in age-old statistical models and theorems. You need to understand the fundamentals of statistics starting from mean, median, mode, variation, and standard deviation. It also helps in dealing with analyzing and visualizing data when building ML models.
Probability theory provides a framework for developing and measuring the effectiveness of machine learning models. Start by learning the basic probability calculation followed by Bayes’ rules, conditional probability, and chain rule.
Khan Academy is your best choice when it comes to learning the math prerequisite. Choose the appropriate modules that cover the above-mentioned areas.
Algorithms
Algorithms form the core of machine learning. They existed even before ML became popular. Most of these algorithms were created by mathematicians during the last decade. Majority of them are based on proven statistical models.
Prediction and classification are two important areas of machine learning. Based on historical data, predicting a real number is a very popular application. Similarly, classifying an image or a data point is a useful scenario. The famous Boston housing prices and MNIST dataset are used during the experimentation with prediction and classification.
Linear and logistic regression form the foundation of ML. Even in advanced use cases involving deep learning and neural networks, these two become important. Invest your time understanding the equation, y=mx+c. Don’t overlook the concepts related to gradient descent, learning rate, loss function, and cost function. They are highly relevant and applicable even in deep learning.
Other algorithms such as an SVM, KNN, Naive Bayes, and others are used for prediction or classification. But, once you appreciate how linear regression works, these algorithms are easy to understand.
Predictive analytics based on linear regression is the “hello world” equivalent of ML. Make sure you are investing enough time in learning this algorithm.
Before you get tempted to open the editor and start coding away, spend time with Microsoft Excel to understand the algorithms. For inspiration, refer to the past tutorials in this series of Machine Learning is not Magic.
Languages
Python and R are two popular languages for developing ML models. If you are an absolute beginner with no background in either, you can choose any of these two languages.
Python is by far the best language for ML. Its simplicity lets developers focus on the problem than getting lost in the syntax, semantics, and conventions. The other reason for its popularity is the ability to deal with data structures like lists, dictionaries, and tuples. Python has the best ecosystem of tools and libraries for scientific computing. Learning Python 3.x makes you future proof. Invest time in mastering the syntax, data structures, and file I/O in Python.
If you come from a non-programming background with some familiarity with MATLAB, R may be the best bet for you. Fortunately, many tools that are available in Python have language bindings for R. For traditional statisticians, R provides a familiar approach.
My personal recommendation is Python, which is based on the ease of learning and the availability of tools.
Libraries
The libraries covered in this section are primarily for Python. Though there equivalent modules for R, we will look at Python libraries and modules design for scientific computing and machine learning.
NumPy is a powerful computing library for Python. It is designed for complex data structures such as vectors and tensors. Calculations involving multi-dimensional arrays are handled effortlessly by NumPy. It provides out-of-the-box capabilities for matrix multiplication. When compared to custom code written in Python to perform arithmetic operations, NumPy is lightning fast. It is highly optimized for performance. It acts as the foundation for many other libraries and frameworks. A thorough knowledge of NumPy is essential for machine learning.
Since structured data is available in CSV, TSV, and Microsoft Excel formats, we need a library to access and manipulate this data. Pandas is the most popular Python library for creating flexible data structures from existing sources. It is an essential tool for cleaning up datasets and preparing the data for complex analysis. Pandas integrates well with NumPy and other visualization tools.
After NumPy and Pandas, Matplotlib is the most important library. It is an essential tool for visualizing data. From Histograms to Box Whisker Charts, Matplotlib makes it a breeze to plot data.
Like Matplotlib, Seaborn is another data visualization tools that deserves a place in the data scientist toolkit.
Scikit-learn is the workhorse of machine learning in the Python world. It provides developer-friendly APIs for mainstream machine learning algorithms. Once the data is prepared and normalized, it just takes a couple of calls to Scikit-learn to train and test the model. It acts a simplified abstraction to many algorithms. The helper methods of this module are indispensable for data scientists. Even if you are not using Scikit-learn for training and evaluation, the helper methods save a lot of time involved in the data preparation phase. You cannot claim to be a Python ML developer if you haven’t mastered Scikit-learn.
Tools
An engineer is only as efficient as the toolkit he uses, and machine learning is not an exception. The tooling for ML is still evolving but there are some proven environments that accelerate model developing.
Anaconda is the preferred toolkit to install Python along with all the prerequisites for data science. It comes with a custom installer called Conda, which is used for adding, removing, and upgrading the modules. Standard modules and libraries such as NumPy, Pandas, Scikit-learn are included with Anacoda distribution. It is available for Linux, MacOS, and Windows.
Spyder, which is available in Anaconda, is a nice IDE for data science. The editor supports auto completion, syntax checking, and validation. Spyder includes a variable explorer and Python shell for interactive debugging.
Jupyter dominates the Python tools ecosystem. Formerly known as IPython, Jupyter takes REPL to the next level through its browser-based, interactive experience. Integration with Markdown, HTML, text, and graphics make it the best tool. Jupyter notebooks can be easily shared by developers. Github can render Jupyter notebooks natively, which makes it an ideal choice for collaborative development.
PyCharm is a Python IDE from JetBrains, the makers of IntelliJ. It comes in a free community edition with limited features, and a commercial version that includes features like profiling and advanced debugging.
Visual Studio Code is the latest entrant in the cross-platform developer tools market. It is already a hit among developers, and with tight integration with Python, VS Code is evolving into a data science IDE. As Microsoft increases its Azure ML push, VS Code will become the preferred tool for Azure ML development.
If you wondering where do TensorFlow, Caffe, Apache MXNet, Microsoft CNTK, and other toolkits fit, stay tuned for the next part where I cover the blueprint for deep learning readiness.
Feature image via Pixabay.
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.













