












This is part two of the series of three articles, where we talk about session stores, a common component of most web-based applications, and discuss how you can build in analytics into these session stores so they can enable intelligent decisions in real time.
In the first article, we explored concepts related to session storage and microservices. In this second article, we start with some data structures in Redis that allow for intelligence to be implemented extremely efficiently as part of your session store and some common patterns that need this type of intelligence. These include showing only fresh content to users (filtering out slate content), making relevant/personalized suggestions or recommendations, and pushing out relevant notifications to large groups of users.
Useful Redis Data Structures
Bloom Filters

Bloom filters are likely the most well-known probabilistic data structure. Bloom filters test for the presence and can tell if an item has possibly been added to the filter previously or definitely not been added to the filter previously. In other words, false positives are possible, but false negatives are not. In exchange for accepting false positives you gain immense savings in storage: you need a handful of bits per item, regardless of the sizes or number of items in the filter. So, you can do two operations with Bloom filters:
- Add an item
- Check if an item has previously been added to the filter
Bloom filters in Redis are available through the module ReBloom, which can be either used in the open source version of Redis by downloading, compiling and running the MODULE LOAD command or directly in Redis Enterprise by downloading the package and enabling it in the administrative interface.
The most simplistic implementations of Bloom filters can “fill up,” i.e. as more items are added, the higher the error rate becomes. The ReBloom implementation of Bloom filters are scalable: you specify an error rate, and if you try to add items that would result in an error rate larger than the specified rate, ReBloom will seamlessly create an additional Bloom filter inside the same key. When you check for the existence of an item, it will then check all the internal Bloom filters. This trade-off does result in a heavier existence check operation for Bloom filters that have been scaled multiple times, but it can yield a virtually consistent error rate. Luckily, you can specify an initial size to fit your item cardinality requirements, lessening unneeded scaling.
HyperLogLog
HyperLogLog is a structure that can determine the cardinality of unique items probabilistically. Like Bloom filters, you need mere bits per item and the size of the items are unrelated to the size of the structure. The cardinality of the unique items is an estimate. As an example of the size required and error rate, you can hold 264 unique items (of any size) in ~12kb of storage with an error rate of 0.81 percent. HyperLogLog has three operations:
- Add an item
- Count the unique items
- Merge to HyperLogLogs together
The merge operation will yield a set count of unique items between the two HyperLogLogs (union). As an example, if you merge two HyperLogLogs, each holding the lone item “dog,” and you then ran a count on the newly merged HyperLogLog, the count would still only be 1.
HyperLogLog is one of Redis’ built-in data types.
Bit Counting
Bit counting is not a stand-alone structure, but rather an alternate method of using the Redis String data structure. Redis can manipulate a string value as an array of bits by the index at an O(1) complexity on pre-allocated values. There are many uses for this technique, but we can use it directly to create a time series-like structure.
If you start with a known, fixed point in time and keep count of a specified period of time since this fixed point, you can use set individual bits at correlated indexes. Let’s say your fixed point is Jan 1, 2018, at midnight (2018/1/1 00:00:00), you want to record that something happened at 1 a.m. (1/1/2018 01:00:00) and you’re keeping track of minute periods. In this case, you would flip the 60th bit from zero to one to indicate some activity at 1 a.m.
Redis has a number of commands that enable:
- Counting the first bit set to 1 in an array
- Querying individual bits
- Setting individual bits
- Querying multiple bits
- Accessing multiple bits as numbers of arbitrary bit-width
Bit counting and the bit counting commands are built-in capabilities of Redis.
Session Store Patterns
Let’s explore a few patterns for our session store microservice to implement.
Content Surfacing
Given a content-heavy platform such as a blog, e-commerce or news site, a common goal is to keep a user engaged by showing them new (and personalized) content. This presents challenges as it would involve storing every content piece that the user has interacted with, then finding the difference to a set list. If you insert the content read by the user in the primary database for the site, this would quickly turn into a scaling problem as, for most databases, writing is an expensive operation—with Redis being a notable exception. Then you would need to do another expensive operation to find the difference between the list of content and the list of viewed content. We can do better with a session store and a Bloom filter.
First, any time a user views a piece of content we can add it to a Bloom filter housed in that user’s session store. Second, when we want to surface new content, we can take a list of content pieces and then check for the existence of these pieces in the filter. Checking for presence in a Bloom filter is the O(log n) operation, where n is the number of times the filter has had to be scaled (n will likely be very small, so we can check for the presence of multiple items without worrying too much about performance). Since Bloom filters cannot return false negatives, we know with certainty that the content that is not in the Bloom filter is “fresh” for this particular user.
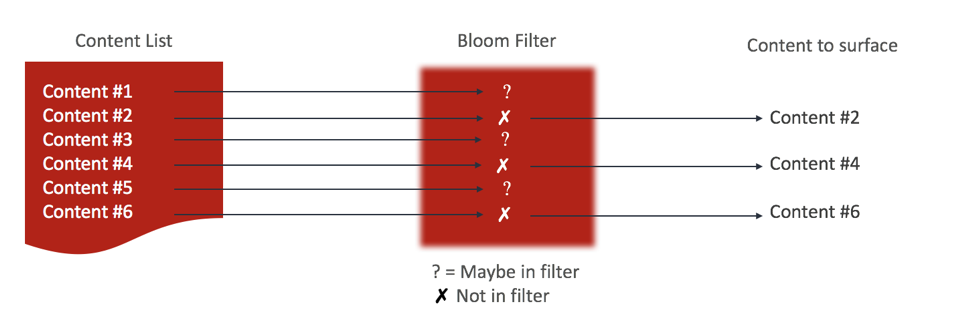
The interesting thing about this pattern is that it can be scaled very easily. The list of content will change relatively infrequently and can be cached from the primary database easily. Each user has their own Bloom filter and the storage requirements are modest, which means that the needs are more related to the size of the user base rather than the amount of content or number of interactions. Finally, in a sharded environment, like a Redis Enterprise cluster, the data and load can be easily shared across multiple shards since it’s made up of small, individual keys per user.
Activity Pattern Monitoring and Personalization
Today’s most engaging and dynamic web experiences are powered by data that users provide to the site, both consciously and subconsciously. We can utilize our microservice to collect users’ behavioral data and then process and utilize that data to create a customized experience for the user.
Firstly, this process is often seen as difficult to accomplish. Analytical data is often collected in another service (Google Analytics, for example) and this data is anonymized. Doing self-collection of this type of data is often infeasible because of the write and storage requirements that are difficult to meet when recording all the data directly in disk-based databases.
Secondly, making decisions on this type of data is deferred to complicated and expensive graph or ML-based solutions. While these solutions often yield interesting results, the data is inferential and locked into black boxes that are difficult to combine with other insights. For example, you might have market research that demonstrates some concrete correlations, but if your ML-based model doesn’t provide output with the specific data that lines up with the market research, you can’t fully utilize your data. Take this example:
| ML Solution | Direct | |
| Input(s) | User behavior | User behavior (Added television and wall mount to cart) |
| Output | User would like item #123, … | User would like an HDMI cable |
| How do we know this? | ? (black box) | Market research tells us that 9 of 10 people who purchase a TV and wall mount also purchase a new cable |
To accomplish this type of monitoring, we need to utilize many of our structures. With a microservice, we have limited amounts of information, but it will be sufficient to gain significant insights.
First, let’s record site activity. We can accomplish this with bit counting, which will tell us not only when activity occurred, but also any discernible patterns in that activity. Initially, we’ll pick our fixed point in time and a time period. Let’s say the starting point is January 1st and our time period will be minutes. Any time a user loads a page during any particular minute, we’ll flip the bit corresponding to the number of minutes since our fixed point; 1500 minutes after our fixed point means we’ll flip the 1500th bit in our activity monitoring key.
Next, we’ll record the unique pages consumed by the visitor in a HyperLogLog, simply adding the URI to the HyperLogLog. Likewise, for every page consumed by the visitor, the URI is added to a page visit Bloom filter. We’ll also increment a simple Redis counter on every page visit.
All of these operations are done on each page visit — this might sound like quite a bit, however, all of these operations are lightweight.
With this information, we can start combining them into specific insights. For example:
- Is this the first time a user has visited a specific page? Check the URI in the page visit Bloom filter.
- New to the site? The HyperLogLog count is 1 and the page is not in the Bloom filter.
- Inactive for the last five minutes? Sum the last five bits of the activity bit counter. If 0, the user hasn’t been on the site in the last five minutes.
- Visited a cluster of pages? Check the Page Visit bloom filter for this cluster.
Given our previous example, let’s say the Cart Add confirmation page has a URI that looks like this:
1 | /added/[primary–item–category] |
So, we have two URIs that could look like this:
1 2 3 | /added/tv /added/tv–mount |
When the user visits the Purchase Confirmation page, we can check the page visit bloom filter for various combinations, including our TV & TV Mount combination. If these match up, then we can suggest an HDMI cable for the user to complete the purchase. This can be accomplished in real time and without having to record each interaction verbatim. It should be noted that we’re relying on a positive presence test in a Bloom filter; consequently, it’s possible that false positives will occur. Recall that the ReBloom implementation can grow while keeping the error rate at an acceptable level, preventing an ever-increasing false-positive rate as the filter fills. Additionally, since we are checking multiple items and the error probability is independent on each check, the error rate on the combination multiplies for each check.
Assuming that we have set up a Bloom filter in ReBloom with the default error rate (0.01 or 1/100), the probability of both items being false positives is much higher for a given Bloom filter state. Finally, in this use case, it would be acceptable to suggest an item that isn’t perfect: who hasn’t had that happen while doing online shopping? It is a tradeoff between accuracy and speed /storage efficiency that must be weighed for each individual use case.
Privacy is obviously a concern when it comes to monitoring behavior. Users often feel a sense of unease when they realize that a site may be tracking the pages they visit. The thought of a nefarious third party gaining access to this information is disconcerting. An interesting aspect of probabilistic data structures such as Bloom filters or HyperLogLogs is that they are intrinsically one way—it is impossible to extract the information put into them directly. If through some means, a malicious third party gained access to the Bloom filter or HyperLogLog data in the session store we’re describing, they would only be able to query items (URIs, in this case), not get a list of items. While this shouldn’t be considered a form of encryption, this configuration makes you a much less appealing target when the malicious actor has to approach it as a needle-in-a-haystack exercise.
Group Notifications
Let’s say your website has groups of users and a notification system. Sending notifications to a single user is simple enough: you have a list of notifications and a status (read/unread). Each user has his/her own list. Group notifications, however, present some challenges. When sending a notification to a group, a new notification is inserted to the personal notification list of each user. This is problematic. Pushing notifications to a large group of users requires a write operation for each user which might be fine for small groups but imagine groups with millions of users. When a user has seen the notification, you need to set the status from unread to read, which would involve touching the primary database.
To make this more efficient, let’s rework this pattern. First, group notifications are stored in a simple List data structure for the entire group. When you want to add a notification, simply add one item to this structure. This becomes an easily cacheable piece of data since it will change infrequently and is the same for all users. Next, we have a Bloom filter for each user stored in their Redis-backed session. When the user checks the group notifications, you take the first n items from the list and check for their presence in the Bloom filter — seen items are present in the filter while unseen items are not. In this case, we assume everything has been seen unless the notification is not in the filter.
This process is very lightweight. Adding notifications to a group is merely a single update that affects every user in the group, no matter the size of the group. Marking “read” occurs fully in the session store and is on a data structure that is only linked to a single user, which means it can be scaled effortlessly. The storage requirements are minimal and checking for the read/unread status consists of some simple hashing functions followed by querying only a very few bits.
While some of these patterns may fall into the ephemeral category, notifications fall into a class of data that should be session based (unique to a single user) and always persisted. Redis Enterprise is uniquely positioned to fill this role as it allows for persistence through in-memory replication. Pairing this with one-minute snapshotting persistence can create a layered durability where no single event can take out your in-memory database and, in the event that all nodes fail, you’ve got a copy that is no more than one minute old.
Feature image via Pixabay.
InApps Technology is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Bit.















