










Microsoft has partnered with the principal commercial provider of the Apache Spark analytics platform, Databricks, to provide a serve-yourself Spark service on the Azure public cloud.
A preview of that platform was released to the public Wednesday, introduced at the end of a list of product announcements proffered by Microsoft Executive Vice President Scott Guthrie during Wednesday morning’s Connect() developers’ conference (complete with parentheses) in New York City:
“Our Databricks service that we’re launching is going to be the first Spark-as-a-service of any of the cloud vendors,” said Guthrie during a press conference prior to the event. “It’s built in conjunction with Databricks, which is really the stewards of the overall Spark ecosystem,” Guthrie promised a major online demo during Connect() on Wednesday, slated to feature integrations with SQL Data Warehouse and Power BI.
“Available in preview, Azure Databricks has been optimized for Azure,” said Microsoft’s communications Vice President Frank Shaw, “and combines the best of Databricks and Azure for a truly efficient developer experience, including one-click setup, streamlined workflow, an interactive workspace, and native integration with rich Azure services like Azure Cosmos DB.”
Spark Plugged
Databricks Inc. is the commercial firm sprouting from the originators of the open source Apache Spark project. This morning, Databricks CEO and co-founder Ali Ghodsi told online attendees, “We’ve heard overwhelming demand from our customer base. They want Azure, they want security, they want compliance, they want the scalability of Azure. And they’ve been asking for a long time about this.

[left to right] Microsoft EVP Scott Guthrie, Databricks CEO Ali Ghodsi, and Databricks engineer Greg Owen
Microsoft’s Spark-related announcements Wednesday was not mentioned in a cloud service map it published just two weeks ago [PDF], comparing Azure’s product suite in several categories — including databases, analytics, and big data — to those of Amazon Web Services (AWS0. The word “Spark” was omitted from that document entirely.
Up until now, Azure’s support for Spark has been a sort of on-demand brain transplant for its HDInsight service, replacing its native Hadoop MapReduce streaming processes with in-memory Spark. Meanwhile, AWS’ principal support for Spark comes by way of a system attachment to Elastic MapReduce, enabling customers to spin up Spark clusters directly from the AWS management console. And Google’s Cloud Dataproc (despite a horrendous name) does enable similarly easy spin-up of managed Spark cluster instances.
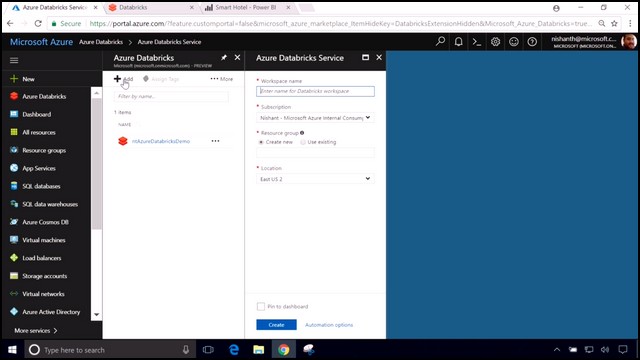
So at least insofar as Spark may be concerned, Azure had some catching up to do. Databricks software engineer Greg Owen may have accomplished parity in one fell swoop, demonstrating for the Connect() audience how a Databricks workspace could be instantiated from within the Azure portal [as shown above]. From there, Owen was able to devise a data pipeline that pulled in tens of millions of active records from Azure-based blob storage, where objects are collectively and abstractly addressed from a mixed plurality of sources.
This way, in Owen’s demo, a hotel could pull up events which travelers are known to have attended in the past — scraped from data collected by ticket sales groups and theatre companies — as a way of devising custom incentive programs to encourage customer travel in the future. Pipeline code can be written in Python, R, or Scala, using a console whose functions appear to be shared with Microsoft’s popular Visual Studio Code cross-platform tool.
Using Python, Owen was able to plug in cross-validation code from Spark’s MLlib machine learning library, without modification. “We don’t have to re-invent any wheels here,” he said. “All this process, which used to take maybe weeks or even months on another platform, we can now do in minutes or days on Azure Databricks.”
End-to-end, to What End?
Historically, Microsoft’s tendency has been to tout its superiority in a given category by presenting the sheer plurality of products it offers in that category (some of which have not always been that different from one another). Sometimes the company has neglected to see the opportunities of how its own products could be used together, perhaps as an unforeseen game-changer.
During their recent press conference, InApps asked Microsoft officials to provide one example of how the tools being announced Friday could be used in an “end-to-end” scenario, as Scott Guthrie repeatedly stated they could.
“When we think about enterprises modernizing their applications to the cloud,” responded Corporate Vice President for Visual Studio Julia Liuson, “one of the key trends we’re seeing is really enterprises starting to use microservices to break down their applications into components that can really leverage the latest DevOps practices, to really speed up the delivery of value to customers. Leveraging the cloud infrastructure to really have the hyperscale, to reach all the customers you want to reach.
“When you think about that journey, how you put the entire application together,” Liuson continued, “requires very strong infrastructure support for the elastic cloud, a great set of development tools to help you and development teams to be productive in this new way of developing for microservices and DevOps practices. And I really think that, for us in the Visual Studio family together with Azure, we’ll have a super-complete set of tools to help developers and development teams in that journey.”
One such tool to which Liuson may have been alluding is its public preview of the AKS edition (now with a “K”) of Azure Container Service. At present, managed Kubernetes is AKS’ default orchestrator, with Docker Swarm and Mesosphere DC/OS now being offered as “alternative orchestrators.” Microsoft unveiled this preview in late October, and promises to be the Azure equivalent of Google Container Engine (GKE), and the recently announced Pivotal Container Service (PKS).
Liuson having clearly pointed out AKS’ ability to manage microservices-based operations, raises the question of whether Azure Databricks and AKS can run together — or, in an absolutely perfect world, whether Databricks could be staged within a Kubernetes-managed environment on AKS. It’s a question which InApps presented to Microsoft, and to which the company is still searching for the adequate answer, even at the time of this publication.
In the most seamless of all integrations, a Databricks service (which is effectively commercial Spark) could run in Kubernetes, using an architecture that a Google engineer already successfully demonstrated last June at Spark Summit in San Francisco.
Also at Spark Summit, an IBM developer named Haohai Ma explained why a container-based platform — specifically, one orchestrated with Kubernetes — would be beneficial to a Spark environment. First, said Ma, the system can automatically keep track of Spark’s dependencies, and make them available when their containers are mounted. Secondly, Kubernetes can enforce limits on CPU shares provided to Spark executors. And thirdly, containing the instance completely within the container environment also effectively isolates the file system used by Spark (in many cases, it borrows HDFS from Hadoop).
Although Spark’s own online documentation clearly explains how a Spark platform can run on Kubernetes, just the length of those instructions attests to the fact that it’s not a serve-yourself process.
Seamlessness to the Extreme
So a marriage at this deep a level would not be without its initial difficulties. In the meantime, there may yet be hope that Azure Databricks may be seamlessly integrated with something that itself may be seamlessly integrated into AKS.
That hope comes from Microsoft program manager Scott Hanselman. Last September, Hanselman recorded a video demonstrating how its Cosmos DB globally distributed database platform can be triggered to respond automatically to serverless Azure Functions (Microsoft’s counterpart to AWS Lambda). Presently, Azure Functions is being marketed as an easier way for enterprises to deploy scalable functionality without having to deal with an orchestrator.
While such a scenario would appear to exclude Kubernetes altogether, it does point to how easily containers may access very large data stores from Cosmos DB using simple API commands. Indeed, Microsoft touted this very capability in a July 2016 interview with InApps, back when the preview edition of the database was called “DocumentDB.”
A project to build a Spark connector for Cosmos DB is currently active on GitHub. Microsoft itself provided developers with a link to that project on Wednesday, in a blog post which revealed that data exchanges between the two environments take place directly between Spark’s worker nodes and Cosmos’ data nodes, as opposed to some slower intermediate conduit.
It would be an “end-to-end-to-end-to-end” connectivity scenario, if it all works out. But the end product could, one way or another, become a way for an enterprise to deploy very large data constructs on a global scale, with a guaranteed latency of less than one second for any query — according to Scott Guthrie — in a fully managed containerized environment without the use of orchestrator plug-ins. Theoretically, at least, such a service would slash both the time and cost required to deploy a hyperscale analytics app, to mere hours and a monthly fee.
InApps’s Lawrence Hecht provided research for this report.
Microsoft is a sponsor of InApps.
InApps is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Docker.






