












Business intelligence and data management can take a bite out of a company’s time and, coupled with cost, can pose a significant barrier for startups and smaller companies.
The Israeli startup Panoply’s smart data warehouse offers automated self-service data management that eliminates the need for BI teams to rely on IT in order to get answers quickly.
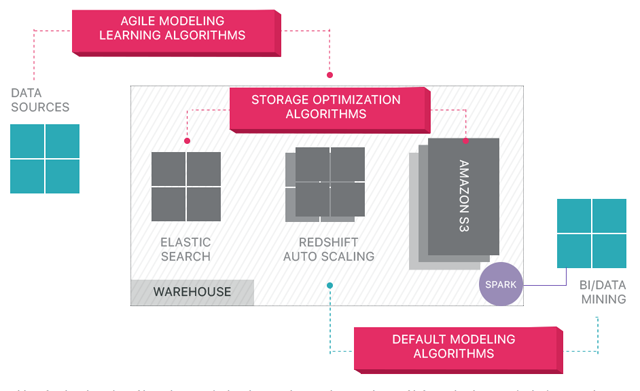
Its cloud-based data warehouse uses natural language processing and machine learning to automate tuning and query optimization while automating elastic storage and CPU scaling on top of Amazon Redshift.
CEO Yaniv Leven describes it as serverless and ETL-less — designed to handle time-consuming infrastructure-management and data-preparation tasks.
“Basically, we say we make Redshift serverless because Redshift at its core requires a lot of management,” said Jason Harris, Panoply director of evangelism.
Kimberly-Clark omnichannel analytics lead Helena Carre maintains that using Panoply with visualization tool Tableau has saved the company $250,000 in two years and eight hours a week in preparing one regional retail report.
But Panoply’s value might be greater for smaller companies that don’t have dedicated data teams.
Justin Mulvaney, the sole data analyst at Spacious, a New York-based startup that offers work spaces from unused buildings, such as restaurants that aren’t open during the day, tells how figuring out how to allocate revenue to different partners used to suck up its executives’ time.
It eliminated hours of data exports and manual file checking by every team in the company. Now each team uploads its data and with a little SQL, he said he can run revenue numbers in just a few minutes.
Self-Service Analytics
Founded in 2015 in Tel Aviv by Roi Avinoam and Yaniv Leven, the company launched quietly in February 2017 and announced general availability last November. Its headquarters is in San Francisco with R&D still in Israel. The company has passed the 100-customer mark and has set a goal of 500 customers by the end of the year. It has raised $14.3 million.
Panoply enables users to ingest petabytes of data through APIs with 150 data sources, including databases, social media and CRM systems. It uses natural language processing for data modeling and machine learning for continuous indexing and storage optimization on Amazon S3. It integrates with multiple BI tools such as Tableau, Qlik and Metabase.
It’s focused on making data analytics easy for business users.
“Our sweet spot is SMBs that have intense data needs but don’t have a dedicated data team,” Harris said, adding that 73 percent of its customers come from non-IT roles such as business analysts and data analysts.
It handles ingestion, data management and extraction for users.
It touts:
- Zero management — No need to wait on IT departments to deliver data.
- Automated ETL — Data is aggregated as it streams in. It automatically discovers data types and data structures and adjusts as needed as the dataset changes.
- Faster queries — Machine learning algorithms detect slow queries and improve performance through data caching.
- Universal data support — It supports structured and semi-structured data. It identifies data formats like CSV, JSON, XML and many log formats and flattens nested structures into different tables with a one-to-many relationship.
- SQL — Just use SQL. No programming languages are needed to transform data.
- Full elasticity — Panoply can auto-scale, distribute workloads, perform seamless storage and performance optimizations, including metadata and query executions.
- Enterprise-grade privacy and security — Secure multi-step authentication and access control, and industrial-grade encryption for both data in flight and on disk.
“Whether it’s scaling, node selection, maintenance, monitoring, backups — we handle all that,” he said. “If a person wants to write a query, but doesn’t know how to write an efficient SQL string, we can help do that.”
Amazon announced Aurora Serverless at AWS re:Invent 2017 last December, however Harris lists its main competitor as Snowflake. It also has partnerships with competitors Periscope Data and Stitch.
A collaboration with Stitch and Chartio has produced the automated cloud data stack, a three-click way to initiate a warehouse, bring in data and have visualizations in minutes, Harris said.
He cites Panoply’s differentiators as predictable pricing, ease of use and speed.
In tests run by Tableau, it found a 10x performance boost in rendering visualizations using Redshift-Panoply-Tableau as opposed to just Redshift and Tableau.
Panoply is designed to optimize automatically based upon the usage patterns of the person using it without human intervention. The more frequently the data is queried, the more deeply the platform understands the data and can use machine intelligence to improve performance.
It applies distribution and sort-key setting, compression, query, and view materialization optimizations during the learning process.
“We auto-materialize views, so if we see a customer running the same query over and over again, we’ll write that to memory rather than having to go to disk every single time,” Harris said.
It uses both cached results and materialized views, depending on user statistics such as usage, runtime and frequency from queries to determine which queries or views should be materialized or cached.
InApps is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Metabase.






