












One of the Apache Software Foundation’s newest top-level projects, Trafodion isn’t new at all, but it is finding renewed interest by becoming an open source project, according to Suresh Subbiah, a member of its project management committee.
The technology was created at Tandem Computers more than 20 years ago. Originally built for banking, at one time it was used for most ATMs, according to Subbiah. It’s well-suited for organizations that need a database with high availability and scalability.
The name Trafodion, meaning “transactions” in Welsh, speaks to its roots in online transaction processing (OLTP).
Tandem was bought out by Compaq, which in turn was acquired by HP in 2002. At HP, it was known as SQL/MX, and the company began using it internally as a back end to generate reports, leading to the development of OLAP (online analytical processing) capabilities, bringing it into the growing market for hybrid transactional and analytical processing (HTAP) — databases that can process transactions and run analytics simultaneously.
At one point, it competed well with SAP HANA and Oracle, Subbiah said, though HP eventually decided to sunset development on it and donated it to ASF in May 2015.
Trafodion’s features include:
- ANSI SQL support, building on existing SQL skills;
- Distributed ACID data protection, guaranteeing data consistency across multiple tables and rows;
- Compile-time and runtime optimizers, delivering performance improvements for OLTP workloads;
- Parallel-aware query optimizer, supporting large data sets;
- Apache Spark integration, supporting streaming analysis;
- Interoperability with existing Apache Hadoop tools and solutions, such as Hive, Ambari, Flume, Kafka, and Oozie.
- Apache Hadoop and Linux distribution neutrality.
It’s being used at companies including China Mobile, China Unicom, Dell EMC, Esgyn Corp. and Millersoft.
The move to open source has meant switching from a proprietary storage engine to HBase, which makes it integrated with Hadoop and HDFS.
“That gets you a lot of things, like the scalability of Hadoop,” Subbiah said.
It also can run on Hive, Hadoop’s default data warehouse software.
The differentiators for Trafodion, according to Subbiah, are its combo of Hadoop and SQL, both widely popular, along with its HTAP capabilities.
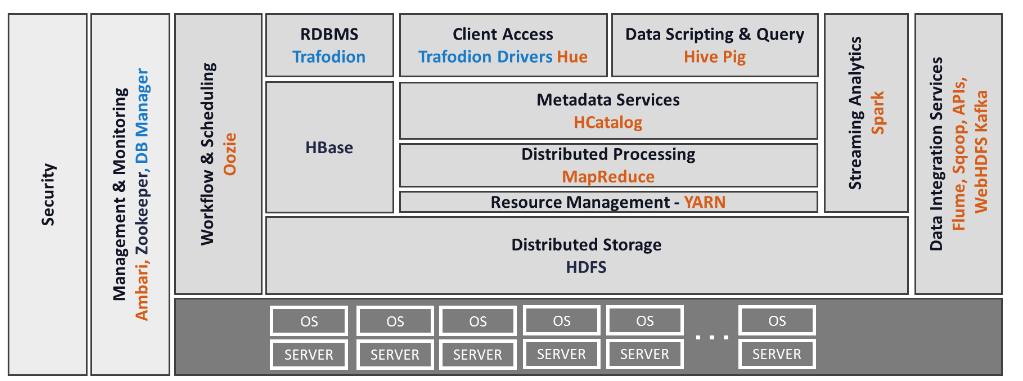
Hadoop, with HDFS, provides the ability to read lots of data, then with HBase becomes with engine for quick lookups, with data was stored in key/value format.
“It was providing similar functionality [to SAP HANA] — you can do transactions or do quick lookups,” Subbiah said. “But SAP databases require you to put the data in tables in their proprietary format. You can’t read Oracle data with SAP. In Hive, its text format, which is the simplest one, the data is just text and anyone can read it.”
However, “HBase, for all its greatness in doing quick lookups, is not that great when you want to read all your data. So say you’ve got gigabytes to terabytes of data to be read for a particular query that requires you to scan all your transaction data … if you try to scan terabytes of data with HBase, there are techniques to make it go fast, but usually, it won’t be as fast as Hive.”
The project has had four official releases since entering the Apache Incubator. A new release will come out in the next month or so.
Subbiah concedes that there are probably 100 SQL-on-Hadoop databases, including Apache Phoenix and HAWQ, which try to address parts of similar database issues. But he believes for Trafodion, perhaps its time has come.
Feature image via Pixabay.






