












Given the massive data breaches of late, especially those at Experian and Facebook — though some quibble over whether Facebook’s should be called a breach — knowing where your data is being used online becomes vital.
That was the genesis of San Francisco-based startup Watchful.io, a distributed platform for real-time pattern-matching at scale.
Co-founder Shayan Mohanty said the idea grew out of his own paranoia — wanting to know the moment any of his information was leaked on the internet — which he turned into an open source project called pasteye.
“How can you pull that data in really quickly, scan for patterns really fast? Doing this for yourself is pretty trivial, you just build your patterns exactly as you want them, keep them in a list and you just run them each time you get some new content,” he explained.
“But opening this up as a service, there are a few major technical challenges there. No. 1: How do you do real-time regex? If you have a million users and each one has 10 to 20 regular expressions, how do you guarantee everyone will get the results in real time?”
Regular expressions are patterns that might indicate, for instance, an email address, a Bitcoin ID, a Social Security number or a credit card number. But it doesn’t have to be just text, he pointed out. It could be used for binary analysis. You could compile an executable file in zeros and ones. Does it look kind of like this other virus that we know of?
“If you as an organization have a ton of these regexes or if you’ve just had a fat, dense stream of data come in and you don’t necessarily know everything that’s in it, you want to flag certain things, like @company.com that could be potentially malicious. A corporate credit card or a certain key that’s just been issued. All of these are indicative of a potential breach and should be flagged in real time,” he said.
But its use isn’t limited to security. For instance, in bioinformatics, DNA sequences are simply text — G, C, A and T. Finding gene expressions in larger genomes is simply a text scan anyway.
“So we see a lot of benefit of having a scalable technology that will allow you to use these types of tools in a really well-developed environment,” he said.
HPC-level Performance
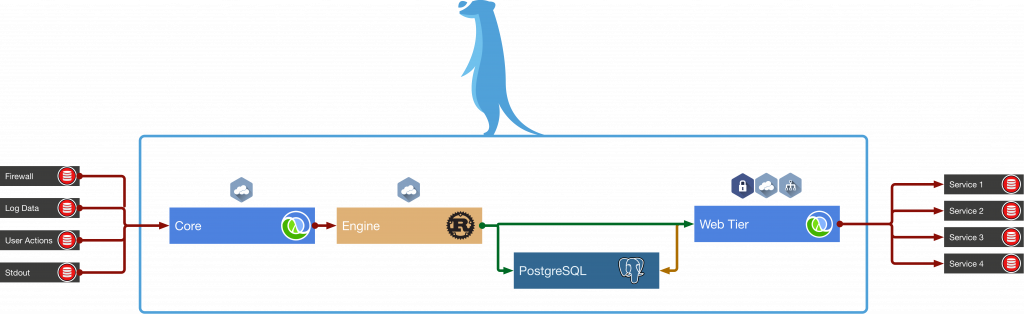
The Watchful technology is built in Clojure and Rust. The engine is built in Rust, which provides control over how the application behaves, such as how CPUs work and context-switching.
Everything else is built in Clojure. Being built on the JVM, it means practically any Java library can be used out of the box.
The main persistence layers are Kafka and PostgreSQL, used as an eventual source of truth for users, filters and matches. It uses a technique called change-data-capture to keep the engines up to date with the latest filters by copying the write-ahead logging from Postgres to Kafka. A “web” component written in Clojure maintains a write-through cache of matches and serves the Watchful API and frontend, and a “core” component serves as basically a plumber — tagging data in flight, recording timestamps, and eventually writing rows to Postgres.
“So in this way we get to use the latest and greatest Kafka connector libraries, always get to use the latest API, but we also have a nice development environment, it’s highly optimized task at hand,” Mohanty said.
In addition, it ships with “wrelay,” a Netcat-like binary written in Rust that allows users to send data into a Watchful cluster without using the RESTful API.
“This is particularly nice to have if you want to stream file contents through Watchful without needing to write code, for instance,” he said.
It comes packaged with Kubernetes for orchestration and delivered to customers as a tarball, so with a with single-command install, you can have an arbitrarily large cluster spin up.
The company’s primary competitors are hardware vendors, Mohanty said. Watchful provides the ability to search and scan applications with FPGA (field-programmable gate array) or GPGU (general purpose graphics processing unit) performance — more than 2 gigabytes of throughput per core — on commodity x86 platforms. And it works on structured or unstructured data.
“The amount of throughput and performance we’re able to provide has normally been in the realm of high-performance computing,” said co-founder John Singleton, who added that the company lowers the barrier to entry, providing high-performance, massively scalable matching throughput against very large data sets and pattern loads while maintaining the linear compute model and real-time results.
Watchful’s open API means it can integrate into existing environments in any language. It can be deployed on-premises, as a cloud service, in hybrid environments and even air-gapped networks.
Smaller Streams of Data
Though unable to name its customers at this point, one large holding company, which owns multiple web properties, is using Watchful for real-time model building, Mohanty said. It uses labeling on production quick streams of data to predict the actions of users across different surfaces. It created flags for certain “milestone” actions, then everything that matched the regexes and everything that didn’t was recorded and used to train the models.
The company’s “slam dunk” use case is SIEM (security information and event management) prefiltration, Mohanty said. Large companies typically funnel practically all their data into a SIEM, at a hefty cost.
“What if, in real time, we can filter out all the low-tier events or specifically highlight high-tier ones and everything else just goes to cold storage?” he asked.
Other use cases include log analysis, open-source intelligence filtration and alerts on publicly available information and real-time indexless search.
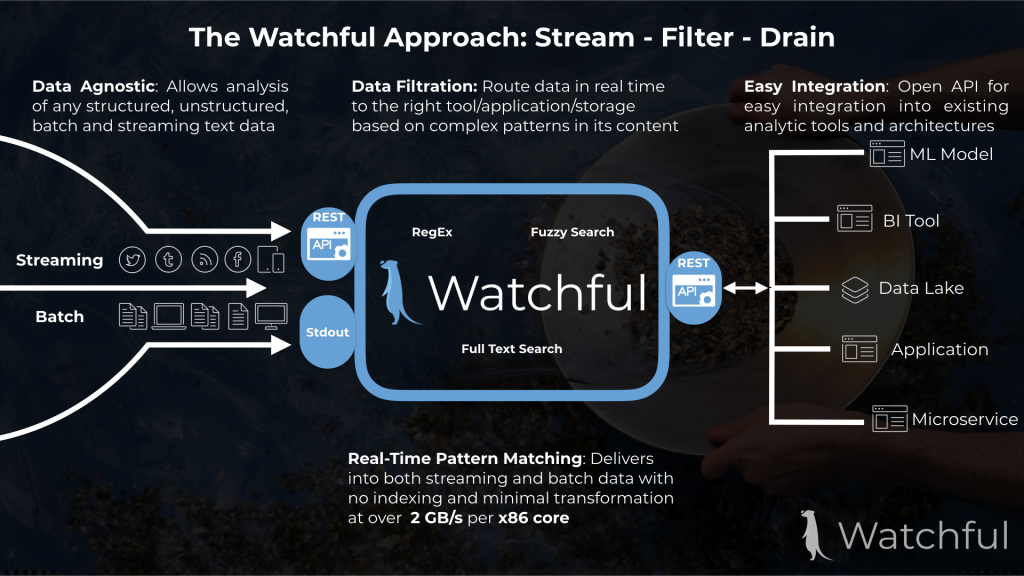
“We are trying to evangelize a new paradigm called “stream-filter-drain” (as opposed to “extract-transform-load”), where data is treated as a large heterogeneous stream and passed through a filter to create smaller, sparser streams of data,” Mohanty explained.
These smaller streams can then be “drained” into databases, data lakes, microservices and SIEMs. Each application only consumes the specific events out of the stream that it cares about, and doesn’t need to get bogged down trying to discern signal from noise.
“In that paradigm, we would expect any ‘action’ to be taken on the drain side — controlled by the user, but in the future we’d like to provide some other flows, such as Window functions/event aggregations, that would more easily enable complex analysis,” he said.
“We see the SFD paradigm becoming fairly important across a number of verticals where heterogeneous data formats lead to complex management solutions. This is obviously apparent in segments like Industrial IoT, where there may be lots of different types of devices communicating with some set of applications constantly, but have varying data schemas.”
Feature Image: “Watchful” by Bill Smith, licensed under CC BY-SA 2.0.






