












- Home
- >
- Software Development
- >
- With Innovative Gaming Moves, Google’s AI Becomes Go Grandmaster in 3 Days – InApps 2022
With Innovative Gaming Moves, Google’s AI Becomes Go Grandmaster in 3 Days – InApps is an article under the topic Software Development Many of you are most interested in today !! Today, let’s InApps.net learn With Innovative Gaming Moves, Google’s AI Becomes Go Grandmaster in 3 Days – InApps in today’s post !
Read more about With Innovative Gaming Moves, Google’s AI Becomes Go Grandmaster in 3 Days – InApps at Wikipedia
You can find content about With Innovative Gaming Moves, Google’s AI Becomes Go Grandmaster in 3 Days – InApps from the Wikipedia website
It seems like an eon ago, but it was only last year in this accelerating era of ever-smarter machines when an AI designed to beat the world’s best human players at the ancient and complexly nuanced game of Go actually accomplished the feat. AlphaGo, the Go-playing AI created by DeepMind, the London-based AI lab that is a subsidiary of Google, surprised many expert observers last year when it defeated the legendary player Lee Sedol, as well as decisively winning all three games against Go world champion Ke Jie earlier this year, before being retired from competition.
But despite its apparent prowess, AlphaGo relied on human expertise to train it. The AI learned from over a dataset of over 100,000 master-level games, in addition to improvements gleaned from playing games many times against itself. Yet, the team that developed it says that by using data from past games may have inadvertently “[imposed] a ceiling” on the AlphaGo’s performance.
Now, DeepMind says that it has developed an even stronger Go-playing AI — AlphaGo Zero — which is capable of learning to play master-level Go and beyond, and it learns on is own, without any human intervention at all.
No Human Data
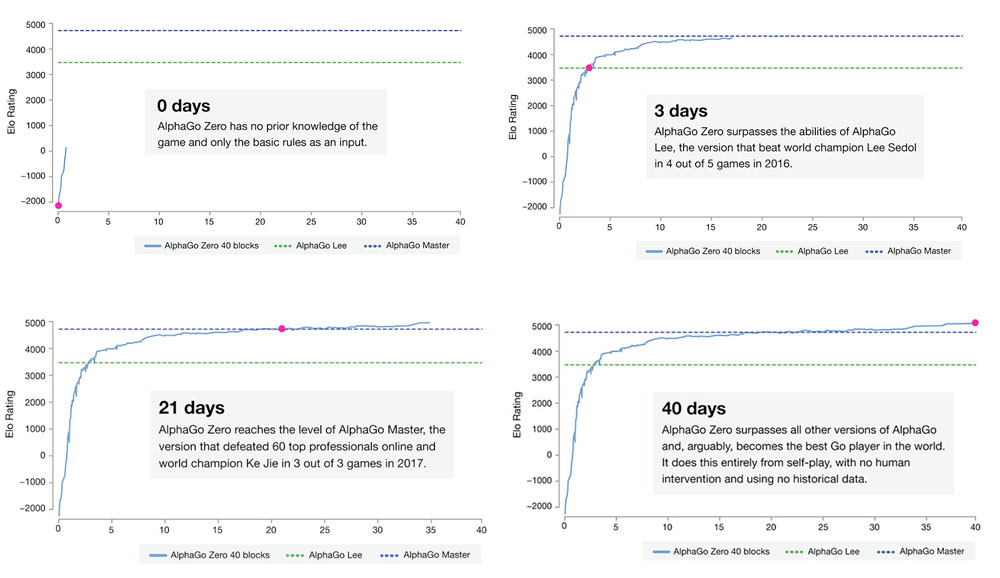
According to the company’s findings, which were recently published in Nature, AlphaGo Zero started out versed only in the basic rules of Go and was able to reach the grandmaster level — in only three days.
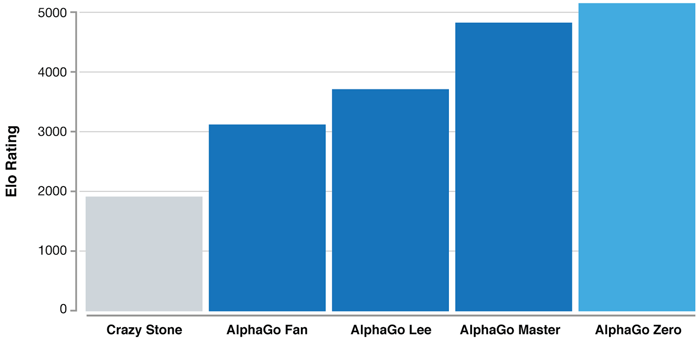
It did so by skipping the human-generated training data that previous versions of AlphaGo utilized, namely, the game data from the thousands of games played by human amateurs and professionals, which were fed into the system. Instead, AlphaGo Zero learns to master the game by playing against itself, using a new form of reinforcement learning to effectively become its own teacher. In doing so, AlphaGo Zero is able to even beat its machine predecessors by 100 to 0, prompting the DeepMind team to call it “arguably the strongest Go player in history.”
Tabula Rasa Learning
There are some interesting differences between AlphaGo and AlphaGo Zero which make the latest iteration so powerful and crushingly efficient. As the DeepMind researchers explain in their paper, Mastering the game of Go without human knowledge, the initial versions of AlphaGo featured two deep neural networks — one “policy network” that selects the next move and a “value network” that evaluates and predicts the winner of the game from each possible position. The value network was tasked with predicting the winner of the games played by the policy network against itself.
Once these neural networks are trained, they are combined with a Monte Carlo tree search — which uses repeated random sampling algorithms to simulate the risks, possible outcomes and probabilities of various moves and counter-moves. The policy network is used to select the moves with the best outcomes, while the value network evaluates the positions relative to the rest of the tree search. This method is what helped AlphaGo decide which move to make, often surprising its human competitor with unexpected moves that hinted at some kind of ghost “imagination” in the machine.
AlphaGo Zero, however, only uses one neural network, combining both policy and value networks into one so that it could be trained more efficiently. This was used in conjunction with a new form of “self-play” reinforcement learning algorithm that incorporates a lookahead search function inside the training loop, meaning the system was able to learn more quickly and consistently. This new system also did away with the random “rollout” games as simulated by the aforementioned Monte Carlo method in previous AlphaGo incarnations, instead relying on its own powerful neural network to analyze moves.
“As [AlphaGo Zero] plays, the neural network is tuned and updated to predict moves, as well as the eventual winner of the games,” explained the researchers. “This updated neural network is then recombined with the search algorithm to create a new, stronger version of AlphaGo Zero, and the process begins again. In each iteration, the performance of the system improves by a small amount, and the quality of the self-play games increases, leading to more and more accurate neural networks and ever stronger versions of AlphaGo Zero.”
The end result: by removing humans from the equation completely, the system is “no longer constrained by the limits of human knowledge” and can learn to start from a blank slate, or tabula rasa, each time from the most powerful player in the world: itself.
Even more surprising is the fact that once AlphaGo Zero surpassed the grandmaster level achieved by the previous strongest version after about 40 days of self-training and millions of games, it then seemed to develop completely unconventional and unanticipated maneuvers — or “discovering new knowledge” as the team describes it. AlphaGo Zero even went so far to discard certain traditional opening moves and sequences in Go, painstakingly developed by humans during the 2,500-year history of the game, in favor of its own innovations.
There are many potential implications here: the foremost being that the algorithm behind such a self-learning system might very well be one piece of the puzzle in developing a strong, general AI that’s capable of mastering many different areas, just as humans might — as opposed to the so-called weak AI that’s only proficient at one, specific task. Yet another advantage would be eliminating the need for large data sets as training fodder for such systems, as these are often costly or difficult to obtain, or in some cases, non-existent.
“Tabula rasa learning is extremely important to our goals and ambitions at DeepMind,” said David Silver, AlphaGo Zero’s lead programmer. “The reason is that if you can achieve tabula rasa learning, you have an agent that can be transplanted from the game of Go to any other domain. You untie yourself from the specifics of the domain you are in and you come up with an algorithm that is so general that it can be applied anywhere.”
If the innovative leaps and bounds that AlphaGo Zero was able to make in such a short time are any kind of indicator, such “general purpose” algorithms could potentially accelerate the discovery of new, unexpected knowledge in diagnosing and curing intractable diseases, solving the growing climate crisis or even help us gain some scientific insights into the mysteries of the universe. It’s still a far stretch from here to that place in time, but such an artificially intelligent future seems even more possible now.
Google is a sponsor of InApps.
Images: DeepMind
Source: InApps.net

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.













