













Multi-Version Concurrency Control, MVCC, is the most popular scheme today to maximize parallelism without sacrificing serializability. It was first mentioned in a Ph.D. dissertation by D.P. Reed in 1979, implemented for the first time in 1981 for the InterBase (later open-sourced as Firebird), and later in Oracle, PostgreSQL and the MySQL InnoDB engine. Many new transactional DBMS also favor MVCC: SAP HANA, MemSQL, HyPer (acquired by Tableau on 2016), and Microsoft’s Hekaton online transactional processing engine. Prior to MVCC, databases used concurrency control approach based solely on locking.
My company’s technology, NuoDB, also uses MVCC and was recently mentioned at the conference for very large databases, VLDB 2017, in a presentation that compared database systems using Multi-Version Concurrency Control (MVCC).
There are several design choices for an MVCC system that have different trade-offs and performance behavior. The design of MVCC legacy systems was influenced by disk-oriented single-core environments. The focus of this VLDB presentation was MVCC scalability in multi-core, in-memory databases when the overhead of synchronization of multiple data versions can outweigh the benefits of multi-versioning. The paper of the work — by Yingjun Wu from the National University of Singapore and Andrew Pavlo’s team from Carnegie Mellon University — analyzed four key MVCC design decisions: concurrency control protocol, version storage, garbage collection, and index management.
Concurrency Control Protocol
Four concurrency control protocols were analyzed:
- The original timestamp ordering (MVTO) algorithm which uses transaction identifiers to precompute serialization order.
- The optimistic concurrency control (MVOCC) algorithm is based on the assumption that transactions are unlikely to conflict. They are split into three phases: read, validation, and write, and the protocol minimizes the time that a transaction holds locks on tuples. This protocol is used in MemSQL, HyPer, and MS Hekaton.
- In two-phase locking (MV2PL) protocol each transaction acquires a lock on the current tuple version before it is allowed to read or modify it. The protocol is used in Oracle, MySQL, Postgres, SAP HANA, and NuoDB.
- The serialization certifier protocol (Serializable Snapshot Isolation, SSI), implemented in Postgres, maintains a serialization graph for detecting and removing dangerous structures formed by concurrent transactions.
Other protocols have been proposed (e.g. speculative read, eager update). But these generally have performance bottlenecks that prevent scaling to many cores.
Version Storage
Version storage describes how the system stores physical versions and what information each version contains. The storage scheme has implications for garbage collection and index management.
Append-only storage can have two kinds of version chains: oldest-to-newest and newest-to-oldest. The oldest-to-newest scheme (Postgres and Hekaton) does not need to update the indexes whenever a tuple is modified. However, read queries can be slow since they may have to traverse a potentially long version chain to get to the most recent value. The newest-to-oldest version chain (MemSQL and NuoDB) minimizes chain traversal since most transactions work on the latest tuple version. When the chain’s head changes all indexes have to be updated to point to the new version. This performance bottleneck can be solved by using a layer of indirection with a map to the latest physical address on the cost of some extra storage.
Time-travel storage (SAP HANA) stores older versions in a separate table. A master version of each tuple is stored in a main table, multiple versions in a time-travel table. Indexes are not affected by tuple updates because they always point to the master version of the tuple. In this storage scheme, the updates copy the current master version to the time-travel table and place the new version in the same slot in the main table.
Finally, delta storage (MySQL, Oracle, and HyPer) stores master versions in the main table and a sequence of delta versions are kept in a separate delta storage. This storage scheme can be memory-efficient for workloads where updates affect a limited number of tuple columns.
Garbage Collection
Periodic pruning of version chains is required in all MVCC systems to manage memory utilization and performance. This pruning is referred to as “Garbage Collection (GC)”. The most common GC method is tuple-level background vacuuming where the system checks visibility of each individual tuple version. Older, unused versions are removed. Transaction-level GC reclaims versions of tuples generated by expired transactions. It uses coarse-grained epoch memory management. New transactions are assigned to the current active epoch. When an epoch expires and has no more active transactions, all tuple versions updated in this epoch can be reclaimed. For this reason, the transaction-level GC needs to keep track of read/write sets of transactions for each epoch.
Index Management
Finally, MVCC index management can use logical or physical pointers in the secondary indexes. The experiments show that the logical pointers provide 25 to 45% better performance than physical pointers when the number of indexes increases.
Research Conclusions
While database research in the past was traditionally focused on optimizing the concurrency control protocols, this study found that both the protocol and the version storage scheme can have a strong impact for scaling in-memory DBMS in a multi-core environment.
The append-only and time-travel storage schemes are influenced by the efficiency of memory allocation scheme. This can become a bottleneck but the authors show that it can be resolved by partitioning memory spaces per core. The delta storage scheme performs well for transactional workloads, especially if the fraction of the modified attributes is small. However, it suffers low table scan performance and is not a good choice for analytical read-intensive workloads.
The authors use the in-memory DBMS Peloton to emulate nine implementations of MVCC as found in several modern database management systems. The Transaction Processing Performance Council’s TPC-C transactional workload extended with a table-scan query is used to demonstrate the overall performance of the various MVCC designs.
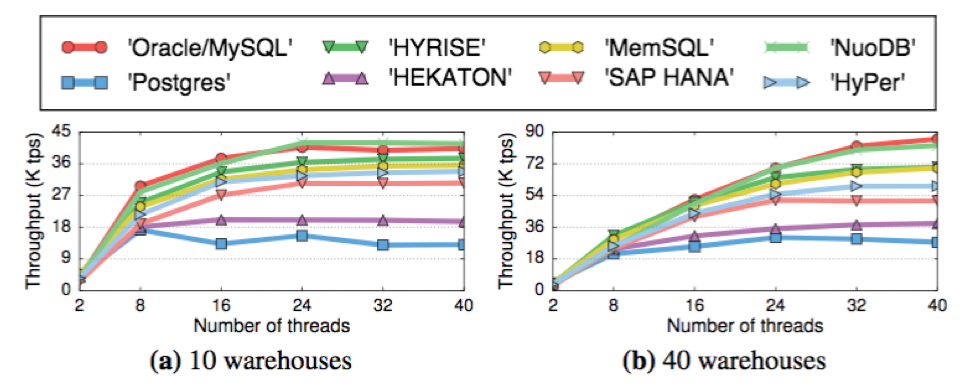
In this experiment, Oracle/MySQL and NuoDB show the best performance in terms of transactional throughput. Both storage schemes — delta and append-only with newest-to-oldest ordering scale well in multi-core, main-memory system. The MV2PL protocol used in both systems provides relatively high performance both in high and low contention workloads.
The next group of systems with lower performance (MemSQL and HyPer) use optimistic concurrency protocol which can bring high overhead during the transaction validation phase (read-set analysis) and a higher number of aborted transactions upon contention. In an isolated experiment, the MVOCC protocol shows a tendency to abort relatively heavy transactions, thus wasting more computational work than other protocols.
The systems with the lowest throughput in this experiment, Postgres and Hekaton, use append-only storage scheme with an oldest-to-newest ordering of version records, which restricts scalability of the system.
Although the delta storage scheme shows good transactional performance (e.g. delta storage with MV2PL protocol in Oracle) it is shown to be worst with respect to latency for table-scan queries since a longer time is spent traversing chains of tuple versions (see fig. 25).
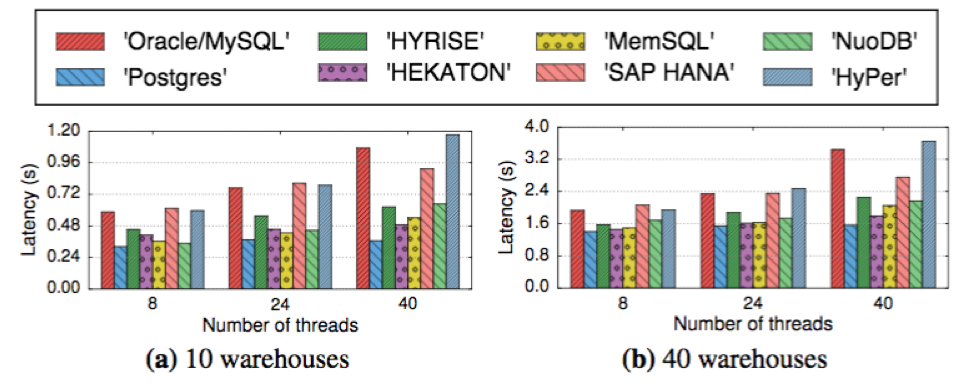
An interesting observation is that the original timestamp ordering concurrency control protocol shows in micro benchmarks the most balanced behavior for varying workloads and contention levels. However, none of the contemporary systems studied here is using this protocol.
The experiments with garbage collection confirm its importance for the overall system performance. The transaction-level GC removes expired versions in batches, reduces synchronization overhead and is shown to provide up to 20 percent improvements in throughput. However, it can cause oscillations in both throughput and memory footprint.
In summary, the MVCC design choices implemented in NuoDB: MV2PL protocol, append-only storage scheme and logical pointers in indexes, are shown to achieve good overall performance both in terms of transactional throughput and latency.
Microsoft is a sponsor of InApps.
Feature image by Denys Nevozhai, via Unsplash.






