













With the rise of Internet of Things, we are entering the era of “things data.” In it, IoT applications process data generated by millions of sensors and analyze it in real time to monitor and control the connected vehicles we drive, the machinery we operate, and smart-cities we inhabit. For software developers, this means there’s a new database workload, one that must offer the following capabilities:
- Ingest millions of data points per second,
- Query data in real-time,
- Handle a wide variety of IoT data structures,
- Execute complex queries such as time series, geospatial, text search, and machine learning,
- Process data at the edge and in the cloud.
IoT is a new data workload. Gartner Research suggests that IoT will challenge us with new data volume, data, and query complexity and integration challenges. And the TPC, the independent standards-setter for DBMS benchmarks, is defining a new mixed workload benchmark for IoT.
At Crate.io, we engineered CrateDB to process IoT data. Here are the DBMS design choices that we made to support the new IoT workload:
Architecture: Distributed, Shared-Nothing, Container-Native
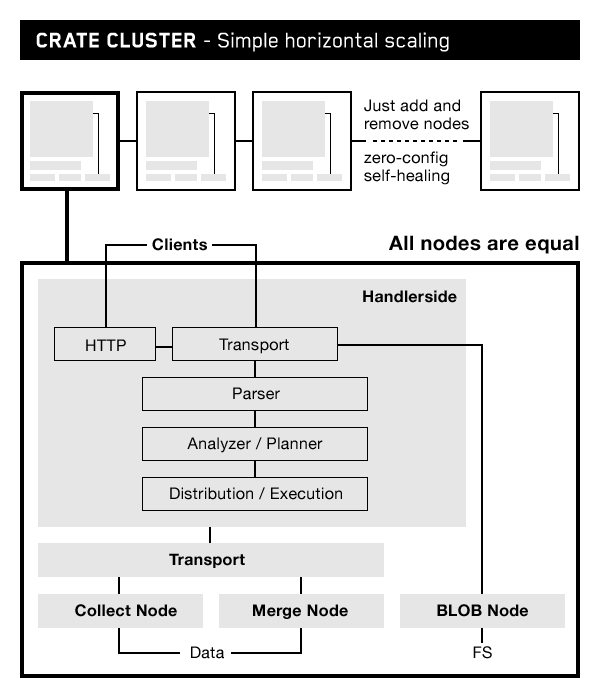
CrateDB operates in a shared-nothing architecture as a cluster of identically configured servers (nodes) that coordinate seamlessly with each other. Execution of write and query operations are automatically distributed across the nodes in the cluster.
Increasing or decreasing database capacity is a simple matter of adding or removing nodes. We worked hard on the “simple” part by automating the sharding, replication (for fault tolerance), and rebalancing of data as the cluster changes size. CrateDB was born in the container era and allows you to scale and administer it easily via container orchestration platforms like Docker or Kubernetes in a microservices environment.
Access: SQL
We chose SQL as the data access language to make CrateDB easy for mainstream developers to adopt. Everyone knows SQL; it’s powerful, and it makes integration easy. CrateDB is compatible with most SQL tools, interfacing via the PostgreSQL wire protocol, JDBC, ODBC, and a REST interface.
A distributed SQL engine is a hard thing to build. It took a few years to reach a viable level of ANSI SQL compatibility, with support for joins, aggregations, indexes, sub-queries, user-defined functions, and so on. We juiced our SQL up with some nice things commonly found with NoSQL, like full-text search, geospatial queries, and nested JSON object columns.
Storage and Indexing: NoSQL-style
The real beauty of CrateDB is how it combines the familiarity of SQL with the scalability and data flexibility of NoSQL databases. We accomplished this by building our distributed SQL engine on a foundation of our own and other open source NoSQL technologies instead of traditional relational DBMS techniques.
CrateDB uses bits of the following open source projects to form its physical foundation:
- Lucene, for storage and indexing, including text search and geospatial.
- Elasticsearch, for masterless clustering and transaction logging.
- Netty, for asynchronous, event-driven, full-mesh networking between nodes.
CrateDB is packaged into a single binary, which is simple to install and start.
Schema: Dynamic
Another benefit of CrateDB’s SQL-NoSQL architecture is schema flexibility. Traditional relational schemas are rigid and changing them is a pain. Each relational record in CrateDB is stored as a JSON document, and those can change structure on the fly.
For example, a global packaging manufacturer collects data from 900 different types of sensors on each of its production lines. In SQL Server, they stored that data in 900 different tables, one per sensor type. After moving to CrateDB, they stored all the readings in just one table. Much simpler. And queries executed 40 times faster.
Writing: High-Velocity INSERTs
IoT systems ingest streams of machine-generated data. We decided on an eventually consistent, non-blocking, data insertion model. This allows CrateDB to insert tens of thousands of data points per second per node while querying the data at the same time.
Data durability and consistency are also important, and we took steps to address those with as little impact on performance as possible. To ensure data durability, we implemented write-ahead logging. For consistency, CrateDB includes record versioning, optimistic concurrency control, and a table-level refresh frequency setting, which forces CrateDB data to become consistent on a periodic basis (every n milliseconds).
Querying: Real-Time Via In-Memory Columnar Indexing
Real-time databases usually require all the data to fit in main memory, but that limits how much data you can manage. Our solution for real-time performance without data volume limitations was to implement memory-resident columnar field caches on each node. The caches tell the query engine whether there are records on that node that meet the query criteria, and where the records are located; this is all performed at in-memory speed.
Distributed query processing also contributes to fast performance, and a query planner that makes very smart decisions about which nodes are best-suited to perform different aggregations and joins.
Platform: Java, at the Edge or in the Cloud
IoT data processing is often distributed, from cloud data centers to remote sites and even onto devices. DBMS portability makes cloud and edge architectures easier to implement, so we wrote CrateDB in Java. Thus, CrateDB can run anywhere, on JVMs in the data center or remotely if internet network latency overhead is intolerable or if data needs to be aggregated before being pipelined to a central cloud instance for wider-scale processing.
What’s Next?
IoT is evolving and so is CrateDB. Our current development focus includes adding support for richer in-database analytics, and building IoT interfaces into CrateDB that support direct device-to-database integration via MQTT for simpler IoT application architectures.
CrateDB is open source, and available for download at crate.io.
Feature image by Élissa Algora on Unsplash.
InApps is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Velocity, Docker, Real.















