












- Home
- >
- DevOps News
- >
- Chaos Engineering Moves to Highlight Business Value

When Netflix first pioneered chaos engineering 10 years ago with its Chaos Monkey tools, the prevalent idea was randomly shutting down parts of a system to see if the whole thing goes down.
Since then, chaos engineering has evolved into a more mature practice that vendors and enterprises are adopting more widely, whether they call it chaos engineering or not. Today’s best practices include initial strategic planning about test designs, concrete plans to turn the learnings from those tests into actionable plans, and communication and collaboration between the development and operations teams. As a result, companies are starting to see real business value from chaos engineering.
“Back in 2011, chaos engineering was just randomly turning off instances,” said Nora Jones, who helped create the scientific discipline of chaos engineering at Netflix and literally wrote the book on the subject. She is now the founder and CEO of the incident analysis platform company Jeli.
In fact, that’s how many people still think about chaos engineering, she said.
“And it’s an easy way to introduce it to folks,” Jones added. “But if you think of it like that, it doesn’t stick in the organization and it doesn’t provide ROI.”
So, for example, a lot of organizations will spend time and money to build chaos engineering tools, which would allow them to turn systems on and off. It’s a fun technological challenge, she said, and not easy to do. It costs time, and money, and eats up engineering resources.
But many companies don’t move past that stage. In fact, compared to actually finding value in chaos engineering, building the tools is the easy part.
“The hard stuff is thinking about where exactly we should be experimenting and why,” Jones said. “And if we find something bad, do we need to fix it? You have to prioritize it among your other feature requests and business priorities. And how do you know if the thing that you did is a likely thing that will repeat in the future?”

What is prioritizing? read more >>
Prioritizing What’s Already Broken
When it’s done well, chaos engineering can help improve a company’s understanding of how its systems actually work.
In fact, some vendors are moving away from the term “chaos engineering” to focus less on the breaking things part and more on the planning and remediation part of the equation.
Jeli, the company Jones founded, calls itself an “incident analysis platform.” Instead of helping companies break things, it focuses on incidents where things break all by themselves, then figuring out what happened and how to keep it from happening again. Jeli counts job site Indeed and 3D development platform Unity among its customers.
It’s an easier way for companies to get into chaos engineering because they start out by looking at things that are already going wrong. “They find out how their organization really works, rather than how they think it works,” she said.
Doing this initial analysis also helps companies get a handle on collaboration, prioritizing remediation, and even prioritizing budgets.
“And you can’t do chaos engineering without looking at that first,” she said.
Other vendors in the space are coming up with different terminology for this type of testing and remediation. Verica, for instance, calls it “continuous verification.”
But there aren’t a lot of players in the space, Jones acknowledges. Mostly, companies use open source tools or rely on functionality built into the cloud platforms. Amazon Web Services, for example, has its AWS Fault Injection Simulator and Microsoft offers the Azure Fault Analysis Service.
One interesting new vendor, Auxon, which calls itself a “continuous verification and validation” company, is applying chaos engineering principles to self-driving cars and other autonomous systems, like surgical robots.
“The field is really nascent right now,” Jones said.
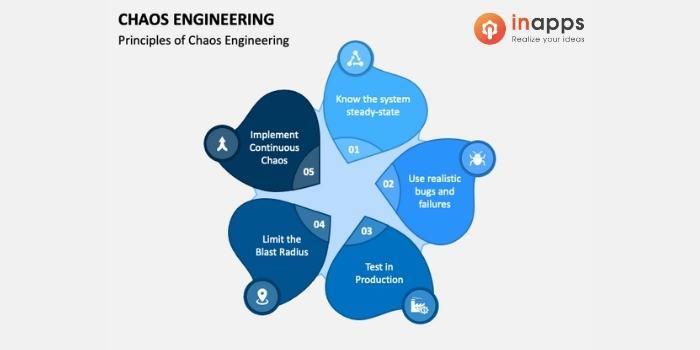
Chaos Engineering as a Feature
In addition to AWS and Azure offering chaos engineering as part of their cloud offerings, other vendors are including chaos engineering tools as part of their service portfolios.
LaunchDarkly, for example, is a feature engineering platform that can be a useful tool in chaos engineering practices. It allows companies deploying software updates to release them in a granular way, starting with small sets of users, allowing teams to quickly roll their updates back if something doesn’t work.
LaunchDarkly counts 22 of the Fortune 100 among its customers, including NBC, GoDaddy, Toyota, Meetup, Adidas, and IBM.
Despite its growing popularity, chaos engineering carries risks, especially when tests are being carried out in production environments, noted Heidi Waterhouse, transformation advocate at LaunchDarkly.
“People say, ‘I don’t want to lose money because production is down,’” she said. “But you’re already testing in production — you’re just not aware of it.”
Real-world chaos engineering happens all the time. Things break, and they break in uncontrolled ways — with potentially disastrous consequences.
“If you think about it, ransomware is someone else performing a chaos engineering experiment on your infrastructure non-consensually,” Waterhouse said. “We give you the tools to do that kind of testing in production safely, in a way that’s instantly reversible and auditable, so you can make sure it’s not as scary.”
Forrester Consulting recently did a survey on behalf of LaunchDarkly about the total economic impact of its platform, focusing specifically on the ability to turn individual software features on or off for customer subsets. The return on investment of the platform was 245%, due to the reduced cost of the pre-production environment, developer productivity savings, and avoided costs of maintaining a homegrown feature management system.
“I look at chaos engineering as a very aggressive form of performance testing at the end of the software delivery cycle,” said Jason English, principal analyst at Intellyx.
The industry is going through a “shift left” process, where more of the testing work happens at the start of the development process. But there’s also a “shift right,” he said: “The development cycle is getting so short that testing is also shifting right — into production.”
And the effectiveness of chaos engineering is helping it expand from where it started out, with web-native companies like Netflix, to more established enterprises, English said.
“You see larger companies, even highly regulated companies, realizing that this is part of an overall compliance check,” he said.
More vendors are offering chaos engineering, under a variety of names, and more will probably do so in the future.
“Any major or minor testing firm that’s doing non-functional testing is doing some form of chaos engineering by default, though they might not call it that,” he said.
NS1, for example, an application traffic management company, has a tool for stress testing DNS servers and networks. The company released it as an open-source project called Flamethrower in 2019.
“Existing solutions didn’t have the features we needed, which limited our ability to perform realistic tests,” said Shannon Weyrick, vice president of research at NS1.
The tool allows companies to simulate realistic traffic patterns, and understand the impact of potential changes to applications and infrastructure in actual production situations, she said. “It can also be used to mimic the surges in traffic an organization might see during a DDoS attack or stress test systems for failover, making it an ideal tool for wargaming and chaos engineering.”
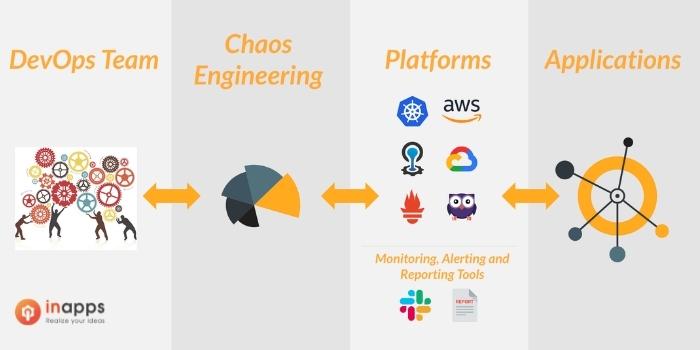
Chaos Engineering’s Business Impact
Another major vendor in the chaos engineering space is Gremlin, whose customers include Charter Communications, JPMorgan Chase, Mailchimp, Expedia, Target, and Walmart.
The way that the Gremlin system works is that Gremlin agents are installed on servers, either cloud or on-prem, where they can create controlled interference on command.
For example, the agents can “black hole” a service, making it look completely invisible to the rest of a company’s infrastructure. Or they can simulate latency issues, packet losses, and packet corruption — a wide variety of problems.
“It’s going to help you reveal weaknesses in your systems so you can prioritize them, start working on them, and make systems and applications more reliable,” said Ana Margarita Medina, senior chaos engineer at Gremlin.
But it’s not about just randomly turning things on and off, she stressed.
“Chaos engineering is thoughtful and planned,” she said. “You use the scientific method. You think about weaknesses you’ve seen in a prior test, or you think about your mental model and look at its fragile points. If I inject latency in my database, am I going to get a caching error?”
After the test is run, it’s time to go back and evaluate the results, improve systems and applications, and rerun the experiment.
“You start experiments really small,” Medina said. “Don’t attack the entire infrastructure at first. Do it with one host. Then you can run it on two hosts, and continue to do that, and expand across the organization.”
And companies don’t have to start right out with production environments, said Jason Yee, Gremlin’s director of advocacy. It can start out with a tabletop incident-response exercise, he said.
“Eventually, you have to take that tabletop exercise and run it in a staging or development environment,” he said. “And, ultimately, in production.”
In April, Gremlin expanded its offering by adding a service discovery tool, which can help a company identify all the services and microservices running in its environment and identify how they relate to one another.

Industry Adoption
In January, Gremlin released the results of a survey tracking how chaos engineering helped companies improve uptime percentages.
Of companies that had less than 99% service availability, half had never run a chaos engineering experiment. Of companies that reported service availability of 99% to 99.9%, 64% had run at least one chaos engineering experiment.
Of companies that reported higher than 99.9% service availability, 74% had run at least one experiment — and 23% were running experiments weekly or even daily.
It’s not surprising that big enterprises are taking chaos engineering seriously.
But it’s happening across the board:
- Forty percent of organizations will implement chaos engineering practices as part of DevOps initiatives by 2023, reducing unplanned downtime by 20%, according to a Gartner report.
- A report published in February by LogicMonitor found that 97% of global IT leaders said that they had experienced an IT brownout, and 94% said that they’d had an outage. More than half of the IT leaders studied said that they saw an increase in IT downtime since the start of the pandemic.
- And according to a report published in April by IDC, sponsored by Zerto, the cost of downtime ranges from thousands of dollars per hour to hundreds of thousands. Companies had, on average, more than 29 hours of unplanned downtime over the previous year.
Chaos Engineering Tests People, too
Chaos engineering isn’t just about pressing a button and having a random part of the system go down to test resiliency.
It also tests the resiliency of the people running the infrastructure, said Mike Loukides, vice president of emerging tech content at O’Reilly Media.
“You can’t build systems that won’t fail,” he said. “That’s impossible. But you can build teams that know how to handle failures. And the way to do that is by giving them practice.”
Chaos engineering also gives teams a deeper understanding of how systems work, and gives companies greater confidence that technical teams possess enough know-how to deal with issues efficiently, said Nuno Povoa, senior security consultant at testing company Eurofins.
And it’s not just useful to help companies deal with operational issues like network outages, he said, but for cybersecurity as well.
“It allows companies to use these tools to tune up their systems so if these attacks actually happened, they can see what it looks like,” Povoa said.
It can give teams experience with cybersecurity disasters in a controlled setting, he said, “as opposed to being breached by malware for the first time and trying to make sense of what needs to be done, when, with whom, and reaching dispersed silos of information to handle an incident.”
For example, Jones recalls an episode from her Netflix days. One of the early tests she ran as a site reliability engineer was to shut down the company’s bookmark service.
“If you watch a show on Netflix and you don’t finish it, you hit pause and come back a couple of days later and it resumes where you left off. That’s called the bookmark service,” Jones explained.
It’s considered a non-critical service, she said, so it seemed a safe one to try chaos engineering on.
“But we were not on the bookmark team,” she said. “And when we took it down, it didn’t bring Netflix down, but we saw a lot of customers having a lot of trouble playing their videos.”
That’s because when the bookmark service was down, Netflix automatically defaulted to thinking that the customer hadn’t watched any of the videos, and kept sending them back to the start.
“It created a really bad experience for the user,” she said.
Then the chaos engineering team handed the result of its test over to the bookmark team. “They might do something with it, or they might not. It’s not in our control,” Jones said.
Chaos engineering team member frustration aside, unclear follow-up means that companies aren’t getting the maximum business value out of their chaos experiments.
That experience taught Jones that chaos engineering requires more strategic thinking about which services to test, more collaboration between departments, and a plan for what to do with the results of a test once it’s completed.
Open Source Chaos Engineering Toolsets
Simian Army
The latest evolution of Netflix’s Chaos Monkey tools
Chaos Engineering Toolkit
Runs and validates experiments
Grafana
Observability platform
WazMonkey
Reboots random Azure instance
Vendors
Amazon’s AWS Fault Injection Simulator
Microsoft’s Azure Fault Analysis Service
Gremlin
Chaos engineering platform
Steadybit
Chaos engineering platform
LaunchDarkly
Feature engineering platform
Verica
Continuous verification platform
Conclusion
We hope this tutorial has helped you in a deep understanding of chaos engineering. It’s not as difficult as you think it. Just go through the entire process once and practically implement it. Also, in case of any queries, you can contact InApps. We would love to help you.

Let’s create the next big thing together!
Coming together is a beginning. Keeping together is progress. Working together is success.














