












Choosing the right database platform(s) for IoT solutions is daunting. First, IoT solutions can be distributed across geographical regions. As opposed to a centralized cloud-based solution, more solutions are adopting a combination of fog computing at the edge and cloud computing. As such, your database platforms must offer you the flexibility to process the data at the edge and synchronize between the edge servers and the cloud.
Second, depending on your IoT use cases, the capabilities you want in your database could range from real-time data streaming, data filtering and aggregation, near-zero latency read operations, instant analytics, high availability, geo distribution, schema flexibility and so on. This article walks you through the four steps in choosing the right database platforms for your IoT solutions:
Step 1. Identify the Data Needs for Your Solution
IoT solutions depend on collection and processing of data from connected devices, making intelligent decisions such as triggering notifications or actions, computing real-time analytics, gleaning patterns from historical data, and so on.
In a generic IoT solution, for discussion’s sake, you could have sensors and actuators that are installed across the enterprise. Thousands of sensors and actuators connect with an edge server. The IoT solution collects the data from all the sensors continuously, makes real-time decisions to control the sensors and actuators, alerts the system monitors of unusual activity and provides a historical view of the analytics to the end users.
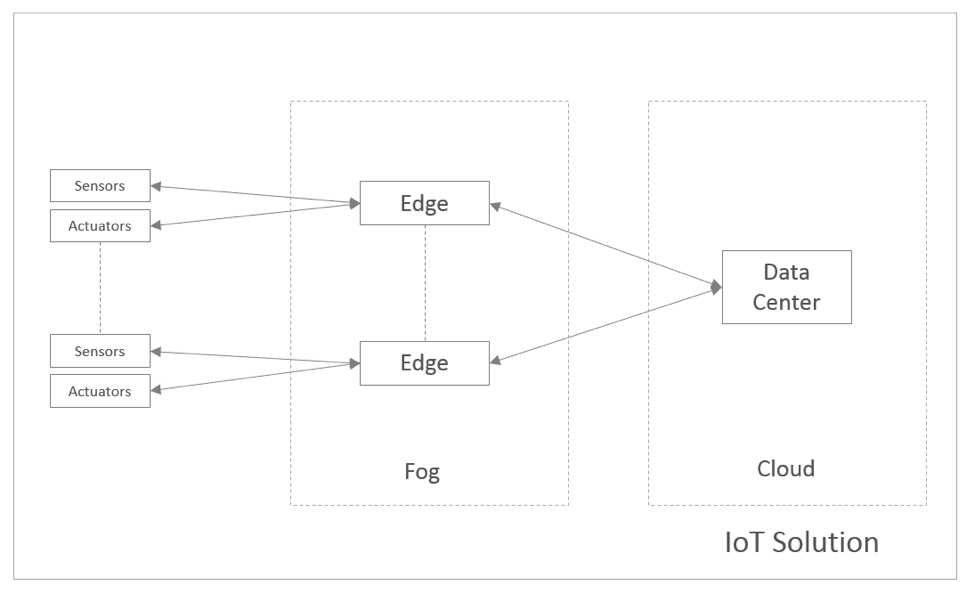
Figure 1. Setting the stage for a sample IoT solution.
Before you decide on the services and the databases that go with them, it’s necessary for you to have clarity on what you are doing with your data, and where. Some questions to help understand and prioritize your data needs:
- What data processing and decision making is delegated to the edge servers?
- Is the cloud solution deployed in one region, or are they dispersed in multiple regions?
- What is the volume of data transferred from the device to the edge server, and from the edge server to the central server? What is the estimate for the peak volume?
- Does the IoT solution control the devices or actuators? If yes, do they require a real-time response?
- What are the business insights derived from the historical data?
Step 2. Breakdown Your Solution into Independent Software Services
In this step, you will design the software services or components that perform independent, specific tasks.
When breaking down the sample IoT solution described earlier into independent services, you may get the design shown in Figure 2. The IoT solution itself is distributed geographically, where some of the components are deployed on the edge network and the remaining components are at a centralized location.
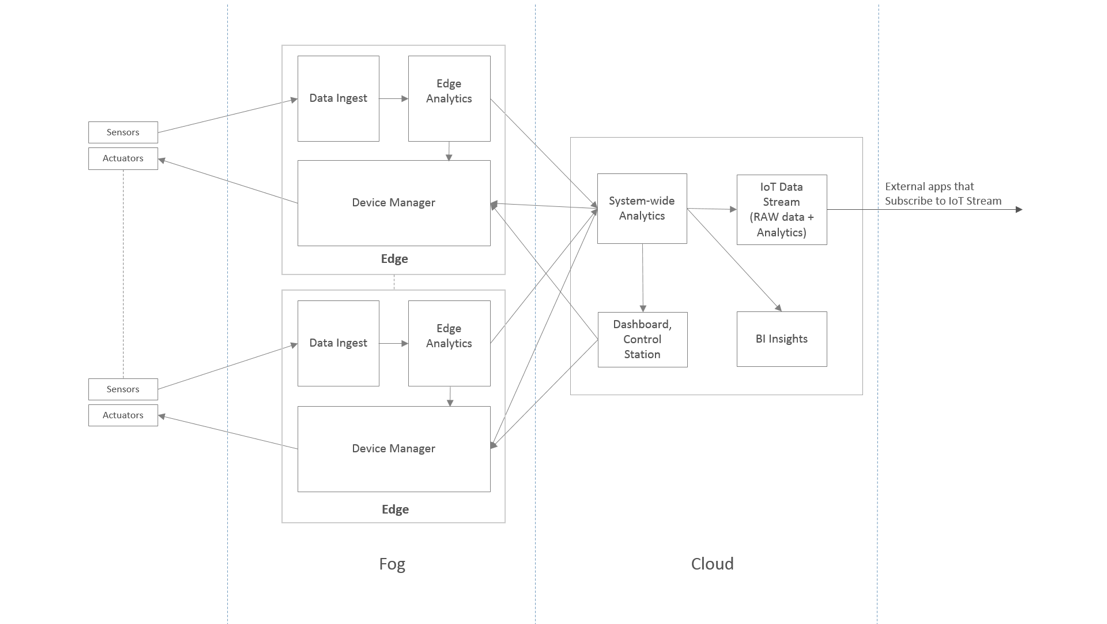
Figure 2. Software services of our example IoT Solution.

Let’s now break up the architecture into services and analyze their responsibilities and the data needs:
- Data Ingest
Purpose: Collect and store logs and messages from the devices.
Database Needs: Support high speed write operations as the data may arrive in bursts, ensure the data is captured not lost under unusual circumstances.
- Edge Analytics
Purpose: Perform data translation, classification, aggregation, filtering, and functions on the incoming data. It’s responsible for real-time decision making at the edge.
Database Needs: Support high speed read and writes with sub-millisecond latency; provide tools and commands to perform complex analytical computations on the data.
- Device Manager
Purpose: Communicate messages to the devices.
Database Needs: Access and deliver messages to the devices with minimum latency.
- System-wide Analytics
Purpose: Collect data from the edge servers and perform data transformation and analytics operations.
Database Needs: Provide commands to perform analytical computations on the data, and store the data long enough as required by the analytics engine.
- C&C Dashboard
Purpose: Deliver visual representation of the current state of the IoT ecosystem.
Database Needs: Maintain data current and accurate, read data with sub-millisecond latency.
- Business Intelligence
Purpose: Run reports, queries and inferences from historical data.
Database Needs: Store data for a long period of time in a cost-effective way; provide tools to query and analyze the data.
- IoT Data Stream Outlet
Purpose: Normalize data to a common format and push them to the subscribers.
Database Needs: Ability to perform data transformation operations efficiently; support for publish and subscribe capabilities.
Step 3: Group your Services by Their Data Needs and Select the Right Databases
The next step will be to choose the right database(s) based on the data for each service. Figure 3 attaches the services from our IoT example to the plot, categorizing them by how long the data stays in the database and the data read/write speed required by the service.
You will see that the data is constantly coming in and going out of the Data Ingest Server, staying in the database for a very short period. At the same time, the data may arrive in high volume and velocity. Therefore, we need a high-speed database with low latency to hold the data for the ingest service. The business intelligence service, on the other hand, relies on historical data.

Figure 3. Time-Speed Curve
The next step is to group the services that have similar data access characteristics where the objective is to limit the number of databases (excess databases and those that don’t fit your requirements), reducing the operational overhead.
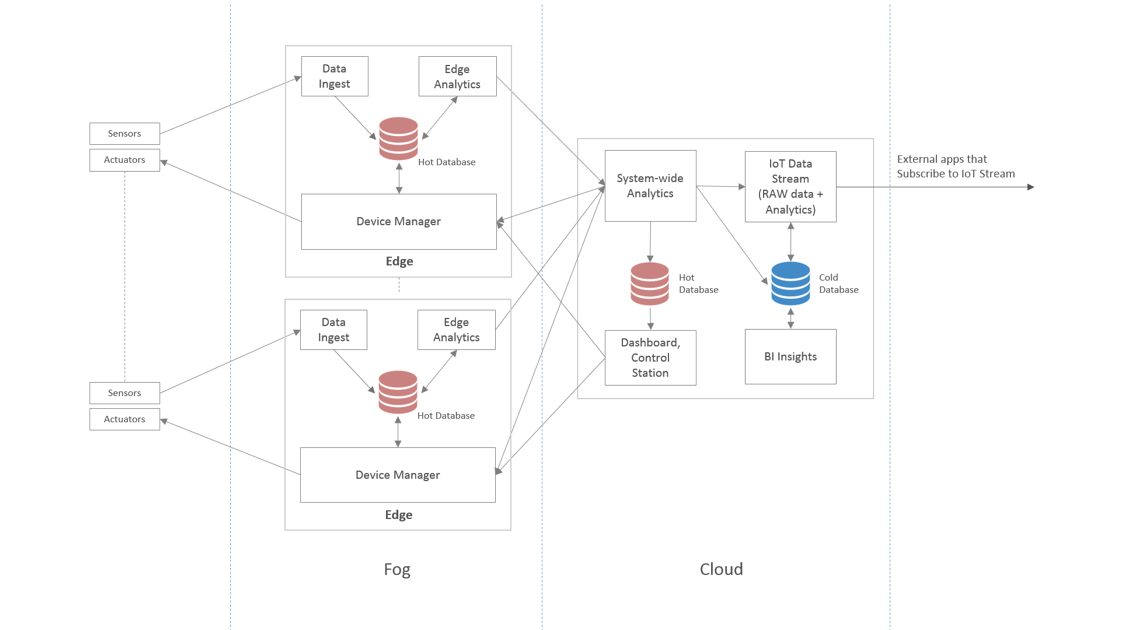
Figure 4. Software services with the databases.
In Figure 4 we group our example services into two main databases – a Hot and Cold database. The databases that hold the hot data are deployed close to the IoT devices to minimize the network latency. The database choices for hot and cold data are:
Hot database: As the cost of RAM gets more affordable, an in-memory database is often a good choice. In-memory databases deliver data read and write capabilities with the least latency. When choosing a hot database, these additional features and capabilities will help you narrow down your selection:
- Flexibility with data formats — helps you support a wide range of devices and communication formats
- Querying capabilities — enables you to run efficient queries in real-time
- Messaging and queueing — drives communication and data exchange
- Tiered memory model — provides a cost-effective memory model and yet high performance
- High availability and disaster recovery — helps you stay in business all the time
- Geo-distribution — serves geo distributed IoT deployment
- Binary safe — helps you save binary data
Cold database: The historical data for IoT solutions may grow to multiple terabytes and may exceed a petabyte in some cases. The popular choices to store historical data include storage solutions on commodity hardware. The queries typically follow the map-reduce pattern. Often, the historical data is also indexed in a search engine for pattern matching and data aggregation. If you are storing the data in the cloud, check with your cloud provider what would be the most cost-effective data storage solution in your region.
Step 4: Evaluate Cost, Resource Efficiency
Classifying the databases into hot and cold helps you in narrowing down your database choices. For most IoT use cases, one high-speed database could satisfy all the requirements for your hot database. In case of the cold database, the options may range from relational databases to data lakes. A common mistake designers make is creating a polyglot architecture with a specialized database for each service. This increases the complexity of the application stack and the operational overhead and cost.
The total cost of owning a database is a function of many parameters. The cost of the database itself is a small portion of the cost. Here are some of the costs:
- Database license cost: The cost could be a function of the number CPUs, number of shards in the cluster, database size, throughput (maximum number of operations per second), time (annual, monthly, hourly, etc.), features for high availability and recovery, availability in multiple regions of the cloud, etc. If you are using a database that’s available as open source software, depending on the type of license the database cost may even be nil.
- Infrastructure cost: The infrastructure cost depends on the resource efficiency of your database. For example, a lightweight, thread-safe database may perform a million read/write operations per second with just two commodity servers, whereas a traditional database may require more servers to give the same result. In addition to database efficiency, your cost of hardware is a function of throughput, number of CPUs, RAM, data size, flash storage, network cards, etc. Database architecture for high-availability also plays a role. For example, a quorum based failover architecture would require only one copy of secondary server, but a non-quorum based architecture will need two copies of data to avoid split-brain.
- Data loss cost: Having a proper insurance against data loss is extremely important, especially for commercial IoT solutions. Your total data loss cost is the sum of:
- Loss of business
- Probability of losing the data * cost of restoring data
You could offset some of the cost with a proper SLA with your database vendor.
- Operational overhead: Automation is the mantra for success. A database that offers controls to automate operations such deployment, provisioning, failover, scaling, data partitioning, and backup and recovery, monitoring and alerts among many other things will help operate efficiently.
Conclusion
When it comes to choosing the right database for your next generation IoT solution, it’s quite easy to get lost with the plethora of databases available today. However, if you break your solution into component services and understand their database needs, you can effectively narrow down your database choices. Most IoT solutions can depend on a hot database for real-time data collection, processing, messaging, analytics, and a cold database to store historical data and gather business intelligence. This will make the architecture simple, lean and robust.
As a final note, Redis, the open source in-memory database sponsored by Redis Labs, is a popular choice for IoT solutions as a hot database. It is widely used by the IoT solutions for data ingest, real-time analytics, messaging, caching, and many other use cases.
Feature image via Pixabay.














