













The saga of the cross-industry side-channel attack (Meltdown and Spectre) is not yet over. Turmoil continues as CPU vendors release new microcode and recall previous ones. To understand the extent of the work that still needs to be done, consider the language Linus Torvalds uses about the patches sent by elite open source kernel developers to deal with Spectre — specifically “Indirect Branch Restricted Speculation.”
Development teams are left to sit back and watch as vendors struggle to decrease the performance impact of these fixes. For example, AWS claims “we have not observed meaningful performance impact for the overwhelming majority of EC2 workloads,” yet most big data workloads are heavily impacted.
Unfortunately, there is no immunization for these types of yet-to-be-discovered security flaws, exploits and so on. Attackers are only getting better at what they do while the spoils continue to grow bigger — in the cloud era, remote access gets you the world. However, there are techniques to limit the performance overhead and the risk to cloud workloads. Before we dive into them, let’s quickly recap the problem. Malicious code running on the same CPU as your application can infer the content of your process, your kernel, or your hypervisor. A major step forward in addressing this has been to add another translation step of the virtual address space using a process called Kernel Page-Table Isolation (KPTI).
Instead of running lots of small machines, run a larger virtual machine and own all the possible CPU cores on that box.
The problem with this fix is that it hurts workloads that frequently change context. I/O intensive applications such as databases, streaming infrastructure, and caches are highly vulnerable to the performance impact. Red Hat measured a performance degradation of up to 18 percent on such loads while the CPU-intensive load that keeps spinning in the CPU will not be noticeably impacted.
Indeed, the Redis cache maintainer, Salvatore Sanfilippo, measured a regression that ranges from as low as 8 percent (SET, pipelined) to as high as 31 percent (SET, not pipelined)! This makes sense because in the latter workload there are no batches and thus more context switches.
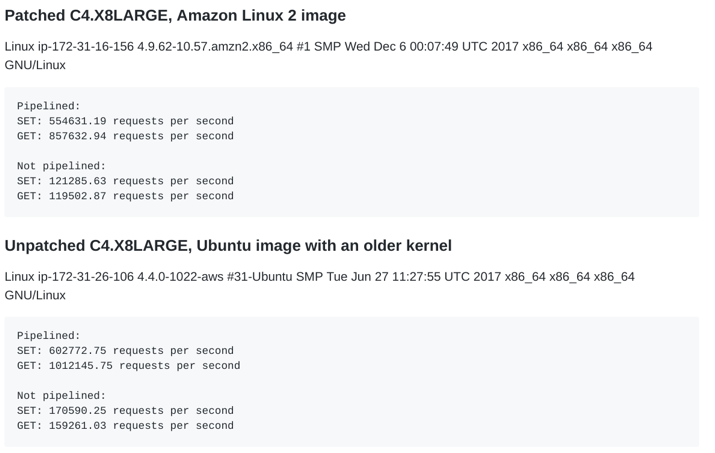
Databricks published very detailed blogs about the performance impact to Spark along with very good recommendations and detailed insight into the breach:
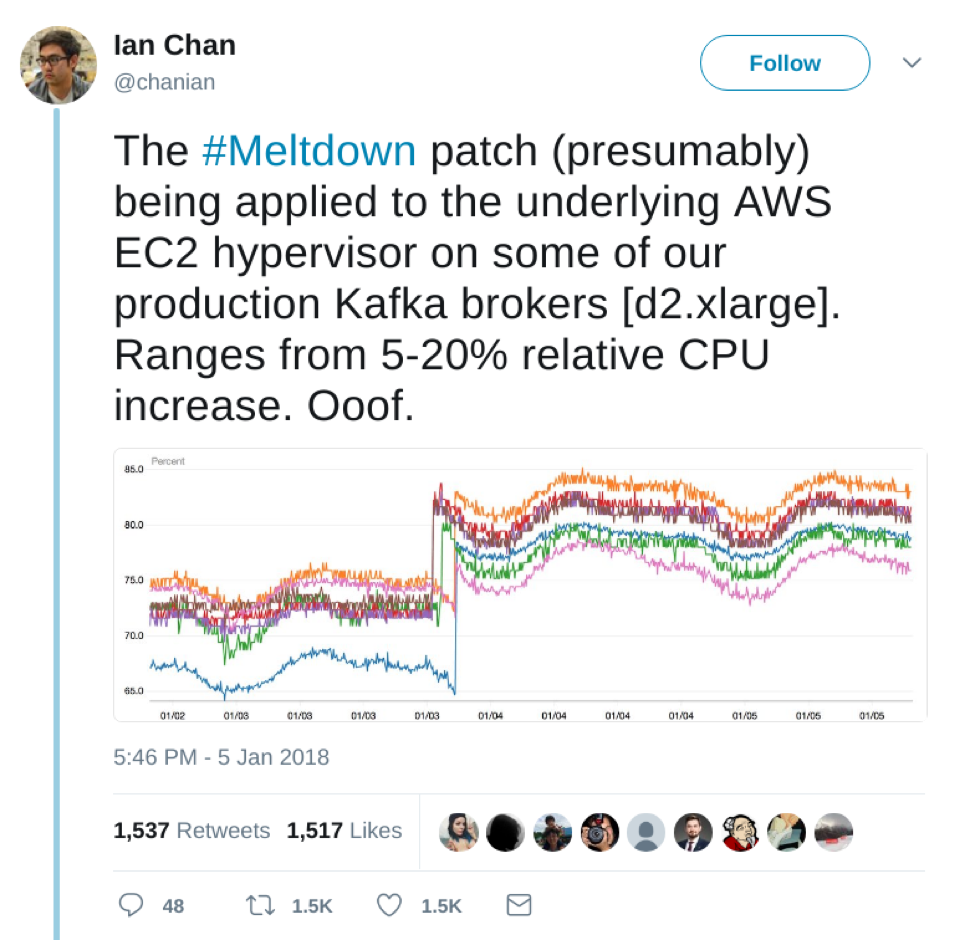
Here’s Kafka’s fair share of the Meltdown CPU tax:
While Intel continues to search relentlessly for a workload that isn’t impacted, keep in mind there is a way to deal with the overhead and also to limit the security risk. In theory, it’s relatively simple. If you wish to lower the overhead of context switches, just minimize them.
It’s possible to reduce hefty context switches between virtualized guests and containers by just avoiding them altogether. Yes, own the entire machine! The noisy neighbor effect (neighboring VMs on the same host that consume an excessive amount of I/O) are a known problem but their security risk is bigger.
Instead of running lots of small machines, run a larger virtual machine and own all the possible CPU cores on that box. You can then divide the machine back using containers that run your own, controlled code, hypervisor, or a framework that can scale up to all of the cores.
Another technique is to reduce your reliance on the kernel. Minimize the amount of context switches by moving more work to user space and batching more actions into the same kernel accesses. Two projects that use this technique while having a high amount of I/O are:
1. DPDK
Intel’s Data Plane Development Kit (DPDK) is a set of libraries and drivers for fast packet processing. It is driven by Intel and you can look at it as a userspace device driver that bypasses the kernel at 100 percent and can be used for layer 3-7 applications.
It offers a minimal impact on performance: Linux accelerator technologies that generally bypass the kernel in favor of user direct access are the least affected, with less than 2 percent overhead measured. Examples that have been tested include DPDK (VsPERF at 64 bytes).
2. ScyllaDB
I’ll give an example that’s close to home. We leveraged the Seastar engine and its asynchronous I/O model when building our NoSQL database. Scylla employs a thread-per-core architecture, meaning that its internal tasks run pinned to a CPU and there are no thread pools or any other multithreading contentions. Every I/O is issued through batched asynchronous system calls through Scylla’s internal I/O Scheduler. The Linux page cache is not used at all. Moreover, due to our polling architecture, system calls are heavily batched and ideally dispatched at only specific intervals called the poll period.
To illustrate the results of this, let’s have a look inside the servers during the execution of an internal benchmark we conducted after the Meltdown fix. Looking at a sample of the CPUs, we see the following profile:
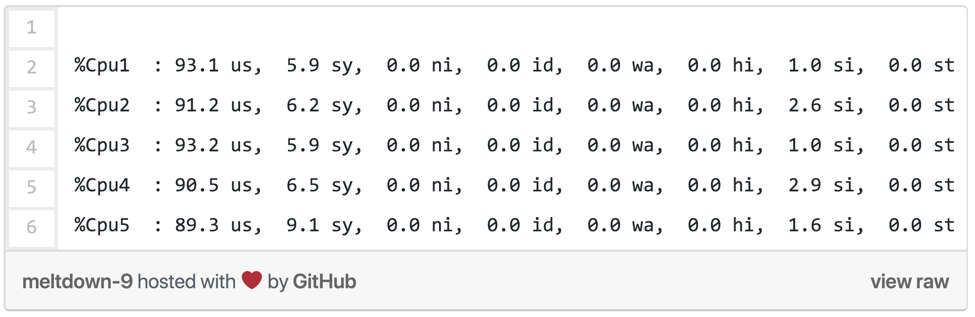
As you can see, the vast majority of time is spent in userspace. This, on itself, indicates that the system has a low number of system calls and context switches. So it’s logical that the Meltdown fixes impact Scylla performance less than they would a thread-based database — if the OS represents only 10 percent of your time, the worst slowdown you can have is 10 percent.
Key Takeaways
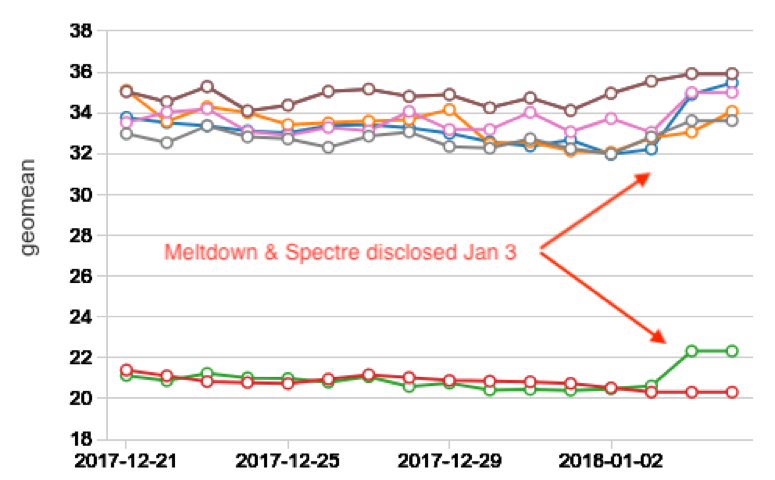
The entire industry was set ablaze by the recent disclosure of the Meltdown and Spectre vulnerabilities. Software fixes for the Operating System are available, but they make every interaction with the Operating System more expensive. Despite varying claims from vendors, the Meltdown and Spectre patches impose a very large performance overhead. Please don’t make the mistake of thinking that you’re somehow exempt from this issue. If you haven’t noticed anything in your CPU cloud monitoring, you might want to first check that you’re measuring the right thing.
How prepared are you for the next storm? If you’ve learned from this experience, you’ll be better prepared to patch your infrastructure as quickly as possible. You’ll have the right configuration management and provisioning tools in place. You’ll make sure you’re not exposed to any zero-day attacks against old software copies. Consider strengthening your security and mitigating risk through segmentation. Group same workload VMs, containers, etc. by their own physical machines. Lastly, minimizing context switches can help prevent performance degradation. Reduce your stack by getting rid of hypervisor/container and visits to the kernel.
Red Hat is a sponsor of InApps.














