













Recent trends in software development leading to greater use of microservices and containers are now rendering some proven and very popular architectures inadequate for many of today’s applications.
To be fair, some of these architectures, such as inter-process communications (IPC) and shared memory, continue to work perfectly well for applications that are able to run on a single server. And others, such as the service-oriented architecture (SOA) and representational state transfer (REST), work well enough for many applications that need to be distributed across multiple servers.
But for the growing number of applications being implemented as orchestrated pipelines of containerized microservices, a more capable and versatile inter-service communications technology is needed. This new technology must meet two objectives: scale beyond the 100’s or 1000’s of transactions or events per second limit of the traditional architectures; and make it easy to achieve the many benefits being promised for the microservices architecture.
This article explores some of the potential pitfalls encountered in the data pipeline needed with microservices, and assesses the streaming platform as a new technology purpose-built for containerized microservices.
Data Pipeline Pitfalls
Ideally, every microservice could be developed in a way that makes it completely self-contained without any direct dependency on any other microservice. Indeed, it is this independence that makes microservices such a powerful architecture because it enables separate software development teams to continuously — and independently — optimize their respective services using whatever development environment works best.
Among the advantages of a well-executed microservices architecture is greater agility and scalability, a simplified development and testing environment, less disruptive integration of new and enhanced capabilities, and more granular service monitoring and troubleshooting.
Containers have emerged as the ideal technology for running microservices. By minimizing or eliminating overhead, containers make efficient use of available compute and storage resources, enabling them to deliver peak performance and scalability for all microservices needed in any application. Containers also enable microservices to be developed without the need for dedicated development hardware, requiring only a personal computer in almost all cases.
The problem is: Microservices running in containers have a much greater need for inter-service communications than traditional architectures do, and this can introduce problems ranging from poor performance, owing to higher latency, to application-level failures, owing to the loss of data or state. This potential pitfall plagues, to a greater or lesser extent, each of the traditional architectures, which all struggle to scale capacity and/or throughput to handle the relentless growth in the volume and velocity of data.
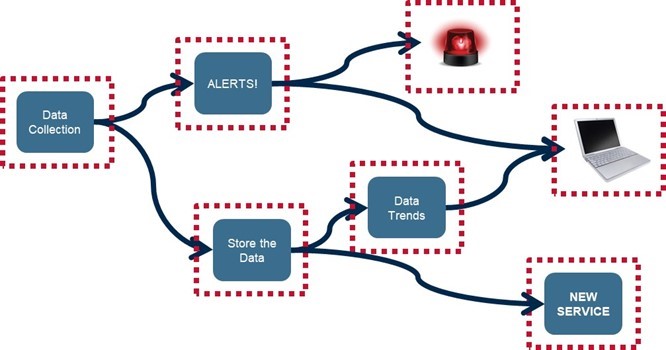
Even a relatively simple Internet of Things application requires multiple services to communicate with one another concurrently.
Consider the typical Internet of Things (IoT) application shown in the diagram. The data being collected must take two separate paths simultaneously—one for real-time alerting and another for historical analyses—which then converge on a common dashboard. Without a capable and consistent means for inter-service communications, this simple example threatens to break the service-level independence whenever a change is made to any of the services involved, or a new one is added.
At the risk of oversimplification, there are two basic means of passing data and/or messages among separate services: queuing and publish-subscribe. With queuing, data is sent by one service and received by another, which affords good security and preserves transactional state, but can make it difficult to scale or implement even a simple application like this one for IoT. With publish/subscribe (pub/sub), data is broadcast or streamed from a publishing service, enabling the stream to be available concurrently to multiple subscribing services.
In addition, the ability to have stateful messages or events consumed by different microservices requires some flexibility in the data types and structures that move through the pipelines. Publish/subscribe streaming platforms enforce no particular data type or schema, and this agnosticism enables the software developers to choose whatever data type and/or structure is best for their application or service.
These two basic approaches have recently been combined to create a distributed streaming platform that supports multiple publishers and subscribers in a way that is secure and scalable—and simple to use with a containerized microservices architecture.
KISS: Keeping It Simple with Streams
The term “distributed streaming platform” was first used to describe Kafka from the Apache Foundation. The contributors to this open source software, commonly used in Weblogs, characterize it as having three important capabilities:
- Publish and subscribe to streams of messages in a way that is similar to how a message queue or messaging system operates.
- Store or persist streams of messages in a fault-tolerant manner.
- Process streams in real-time as they occur.
Another way to characterize these capabilities is the three P’s that make streaming platforms Pervasive, Persistent and Performant. Being pervasive means that any microservice is able to publish data and/or messages in a stream, and that any microservice is able receive or subscribe to any stream. Being persistent means that there is no need for each and every microservice to ensure that the data stream it publishes is properly stored. This effectively makes the streaming platform a system of record where all data can be easily replicated and replayed as needed. And being performant means that the lightweight protocols involved are able to process 150,000 records per second per containerized microservice, and that this throughput can be scaled horizontally by adding more containers.
A major advantage of publish/subscribe streaming platforms is the “decoupled” nature of all communications. This decoupling eliminates the need for publishers to track — or even be aware of — any subscribers, and makes it possible for any and all subscribers to have access to any published streams. The result is the ability to add new publishers and subscribers without any risk of disruption to any existing microservices.
Application-level pipelines are created by simply chaining together multiple microservices, each of which subscribes to any data stream it needs to perform its designated service and, optionally, publishes its own stream for use by other microservices. And scaling an application to handle higher volumes of data is simply a matter of starting up additional containers for whatever microservices are creating a bottleneck.
Its utter simplicity is what makes the streaming platform so powerful:
- Provides a single solution capable of supporting even the most demanding applications,
- Utilizes a single API for “subscribe” from and “publish” to,
- Enables any-to-any connectivity while maintaining independence among microservices,
- Affords compatibility with containers to facilitate scaling with no need to create new images,
- Operates reliably to minimize problems and, therefore, the need for troubleshooting.
In the IoT example above, the streaming platform is depicted by the arrows connecting the containerized microservices. Note how each microservice is able to publish and/or subscribe to multiple microservices, and how new services can be added without disrupting any existing ones. Note also the difference between “streaming data” and a “streaming platform,” with the latter easily accommodating the former, as is the data collection microservice does for all of the “Things” in this example.
Among the most challenging of applications is the consumer-facing web service, and one distributed streaming platform was recently used successfully in a particularly demanding one that required processing up to 20 million transactions per hour with 100 percent transparent and lossless failover across three geographically-dispersed data centers: one on-site and two in the cloud. The application was implemented with the streams flowing concurrently among identical Docker container images running in all three data centers, and with the bi-directional master-to-master database synchronization being provided by the underlying file system.
Getting Started
The distributed streaming platform is both literally and figuratively the “missing link” needed to fulfill the promises of the microservices architecture. It combines messaging, storage and stream processing in a single, lightweight solution. It provides the pervasive, persistent and performant connectivity needed for containerized microservices. And it is remarkably easy to use with its “stupid simple” API for writing to and reading from streams.
By combining the advantages of a containerized microservices architecture with the simple, yet robust, messaging afforded by a streaming platform, organizations will be able to greatly enhance the agility with which they build, deploy and maintain the data pipelines needed to implement even the most demanding of applications.
The technology is so promising that a variety of commercial offerings are now incorporating streaming platforms into their architectures along with other desirable capabilities, such as a database, shared storage, file system replication and security. The result is complete solutions optimized for implementing containerized microservices architectures via open APIs.
A good way to get started is to conduct a pilot using Kafka or a commercial solution that incorporates a streaming platform. While streaming platforms work well in a distributed environment, the pilot can be limited to a single server initially to minimize complexity, and then expanded to multiple servers in a local cluster or the cloud as needed. If the pilot is for converting an existing application, it is best to replace all inter-service communications, such as those using a RESTful API, one at a time, also to minimize complexity.
With a representative choice of the pilot application, proficiency with the streaming platform should come quickly for this powerful yet easy-to-use technology.
InApps is a wholly owned subsidiary of Insight Partners, an investor in the following companies mentioned in this article: Docker.
Feature image by Lyndon Li on Unsplash.






